
💡 Ansible은 yaml 형식뿐만 아니라 ini 파일 형식도 지원한다. 대부분 인벤토리 파일은 ini 방식, playbook은 yaml 형식으로 작성하는 것 같으나 이 글은 일관성을 위해 뚝심있게 yaml 형식 위주로 작성된다.
💡 Ansible은 파이썬으로 개발되었기에 파이썬 모듈들을 통해서 대상 노드들과 통신한다. 따라서 Ansible을 깔면서 파이썬도 같이 깔아줘야한다.
이 글은 ansible의 기초 이론을 대충 이해하고 있다는 가정하에 실습 위주로 작성된다.
환경변수
먼저 ansible 환경변수 파일부터 알아보도록 하겠다.
apt install ansibleansible 엔진은 ansible 명령을 실행할 때 모든 환경 설정 및 세팅이 들어있는 ansible.cfg 환경변수 파일을 참고하여 명령을 실행한다. ansible 동작을 제어하는 환경변수 파일은 경로 상관 없이 ansible.cfg 파일에 구성되어야 한다.
ansible --version 명령어로 첫 확인 시 config file = none 에서 구성 후 디렉토리가 할당된 것을 확인할 수 있다.

구성 파일의 구성 내용도 설정 방식에 따라 우선순위가 존재하는데 아래와 같다
- ANSIBLE_CONFIG 환경변수
- 현재 디렉토리의 ansible.cfg
- 홈 디렉토리의 ~/.ansible.cfg
- /etc/ansible/ansible.cfg

ansible-config --view 명령어로 config file의 구성 상태를 볼 수 있다.
[defaults]
inventory = [인벤토리 경로]
remote_user = [ssh user]
ask_pass = [true/false]
private_key_file = /path/to/your/ssh/private/key
다시 ansible.cfg 파일로 돌아와서 inventory는 인벤토리의 경로 작성, remote_user는 Ansible이 ssh를 통해 통신할 때 이용할 유저 설정 항목, ask_pass는 접속 시 비밀번호를 물어볼 것인지 아닌지에 대한 설정 항목이다.
[defaults]는 ansible의 기본 설정을 정의하는 섹션인데 이외에도 여러 섹션이 존재한다. [inventory], [privilege_escalation], [ssh_connection] 등이 존재한는데 많이 사용되는 것은 [defaults], [privilege_escalation] 이다.
[pivilege_escalation]
become = [권한 상승 여부 -> 기본 false]
become_method = [권한 상승 방법 -> 기본 sudo]
become_user = [권한 상승할 사용자 -> 기본 root]
become_ask_pass = [권한 상승 방법의 패스워드 요청/입력 여부 -> false]
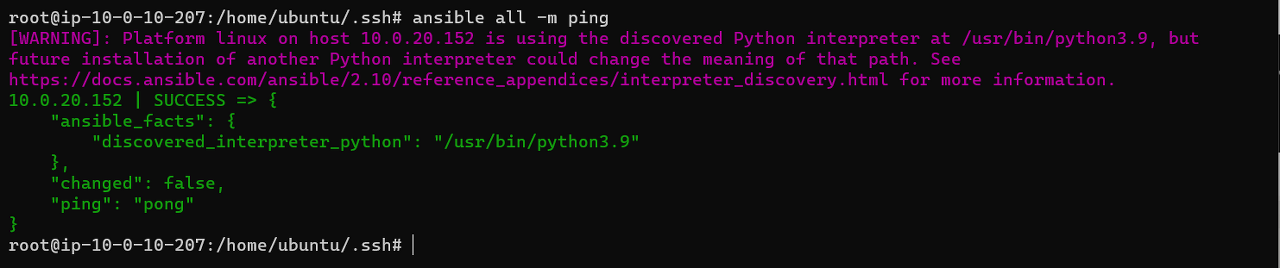
구성 후 간단한 ping 모듈을 통해 통신 시 구성 파일의 정보를 이용하여 통신에 성공하는 것을 확인할 수 있다. 여기서 의문점은 config file을 통해 범용적으로 사용되는 일반 설정을 구성했다면 remote_user가 구성 파일과 다른 노드는 어떻게 관리하지? 이는 인벤토리에서 처리해주게 된다. 이 글을 처음 쓸 때 inventory, config file 순으로 작성하였지만 여기에는 config file, inventory 순으로 작성하여 이해가 안되는 부분이 있을 수 있다. 아래 inventory 글을 보다 보면 이해할 수 있을 것이다.
inventory
💡 /etc/ansible/hosts 기본 파일은 ini 형식의 파일인 것 같다.
ansible이 관리하는 서버의 정보를 담은 파일을 인벤토리 파일이라고 한다. INI 방식 또는 yaml 방식으로 작성되며 기본적으로 /etc/ansible/hosts 파일을 이용하고 다른 파일을 불러오고 싶을 때에는 -i 옵션을 이용한다(여러 파일을 동시에 지정하거나 클라우드, 또는 CMDB에 저장된 내용도 불러올 수 있다). 이 외에도 인벤토리는 세가지 방법으로 지정 가능하다.
기본 설정 파일(/etc/ansible/hosts)에 설정
mkdir /etc/ansible/
vi /etc/ansible/hosts
all:
hosts:
~~~~:
#ini 형식에서는 all을 생략하니까
echo "192.168.10.1" > /etc/ansible/hosts
ANSIBLE_INVENTORY 환경 변수에 설정
vi ~/.ansible/hosts
test_group:
hosts:
~~~:
export ANSIBLE_INVENTORY=~/.ansible/hosts
외부 파일 작성 후 -i 옵션으로 명령어 실행 시 파일 경로 지정
ansible all -m ping -k -i ~/my_ansible_hosts
적용 우선 순위는 3 → 1 순이며 같은 노드가 여러 방식으로 지정되어 있다면 우선 순위가 높은 항목만 task(작업)이 적용된다. 1번 방식은 root 권한이 필요하며 유연성이 떨어져 잘 사용하지 않는다고 한다.
인벤토리에 각각의 호스트를 그룹 지어 정의할 수 있는데 모든 호스트는 하나 이상의 그룹에 속할 수 있다. 이 때 all과 ungrouped는 기본 그룹이다. 이 둘은 항상 존재하지만 명시적이라 실제 파일에 존재하지 않을 수 있다.
| all | ungrouped |
| 그룹에 속해 있는 모든 호스트 포함 | all 에 포함되지 않는 모든 호스트 |
#INI 형식
#YAML 형식과 다르게 ALL 구문 생략
[그룹명]
{IP}
{도메인}
EX)
[BRANCH]
192.168.10.2
www.brach.com
#yaml 형식
all:
hosts:
www.example.com:
192.168.10.21:
[그룹명]:
hosts:
[도메인]:
[IP]:
기본 구성 방식은 위와 같으며 만약 대상 노드의 서비스의 포트 번호가 다르다 [www.example.com:80](<http://www.example.com:80>) 또는, 인벤토리의 변수 선언으로도 지정이 가능하다.
하나의 호스트를 여러 그룹에 중복할당하는 것도 가능하다.
Ansible 공식 문서에서는 거의 기정 사실화로 이 기능을 사용할 것이라고 말하고 있다. Ansible 공식 문서에서는 무엇(애플리케이션, 스택 또는 마이크로서비스), 위치(로컬 DNS, 데이터센터나 배포 지역), 시기(배포판인지 테스트판이지 등등)의 3가지 기준으로 나누는 것을 권장한다.
all:
hosts:
www.idiot.com:
children:
webservers:
hosts:
ns.idiot.com:
east:
hosts:
ns.idiot.com:
위와 같이 중복하여 여러 그룹에 속하게 할 수 있다.
all:
hosts:
www.idiot.com:
children:
webservers:
hosts:
ns.idiot.com:
east:
children:
webservers:
위는 이전의 코드와 동일한 결과를 얻는 다른 코드이다. east에 webservers의 hosts의 내용을 중복 적용하는 것이 아닌 children 키워드를 통해서 그룹을 불러와 과정을 단순화할 수 있다.
또, 비슷한 이름의 호스트가 여러 개 존재한다면 모두 각각 추가하는 것이 아닌 알파벳이나 숫자로 범위를 지정하여 추가할 수 있다. 많이 사용되는지는 잘 모르겠다.
group1:
children:
host1-group:
hosts:
web[01:50].example.com:
host2-group:
hosts:
db-[a:f].example.com
위의 내용은 [01:50] 1부터 50까지라는 뜻으로 web1.example.com~web50.example.com을 한번에 추가한 것이다. 알파벳도 동일한 방식이다.
변수 추가
💡 PARAMIKO 연결 방식은 비SSH PORT(22번 이외의 포트)에 대한 연결에 오류를 일으킨다고 한다
ansible에는 호스트나 그룹에 대해 더 세부적인 정보를 구성할 수 있도록 다양한 변수를 지원하고 있다. 먼저 호스트 당 세부 내용을 적용할 수 있는 호스트 변수부터 알아볼 것인데 ini 형식과 yaml 형식 모두 파라미터는 같다.
아래의 파라미터는 기본적인 **연결 변수(ansible과 host 사이의 연결 방식을 정의하는 변수들)**들이다. 그룹 변수와 호스트 변수로 적용할 수 있는 여러 파라미터들이 존재하는데 이런 점은 배워가면서 정리해야할 것 같다.
| 매개변수 | 역할 |
| ansible_connection | 호스트의 연결 타입, local, smart, ssh, paramiko |
| ansible_host | 연결할 호스트의 도메인 또는 IP |
| ansible_port | SSH 포트 |
| ansible_user | SSH 유저 |
| ansible_ssh_pass | SSH 연결 시 사용할 비밀번호 |
| ansible_ssh_private_key_file | SSH 연결 시 사용할 키 파일 위치 |
| ansible_ssh_common_args | sftp, scp, ssh 와 같은 기본 명령을 사용할 때 항상 추가 설정 |
all:
hosts:
host1:
ansible_host: [ip]
ansible_ssh_private_key_file: [directory]
위와 같은 형식으로 적어준다. 위의 host1 은 다른 호스트들과 구분해주기 위한 구문으로 이 구문을 통해 별칭 지정도 가능하다. host1 → jumper로 변경 같이,,,
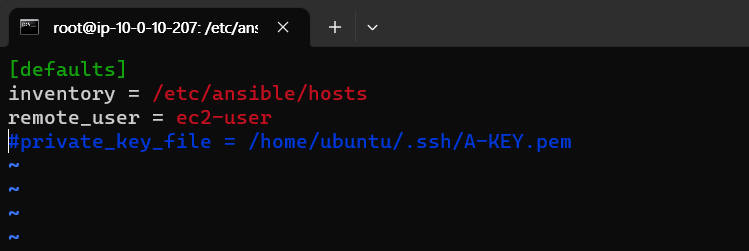
ansible.cfg에서 키 파일 위치를 주석 시킨다.

인벤토리 파일에 호스트 변수를 통해서 정보를 적어준다.
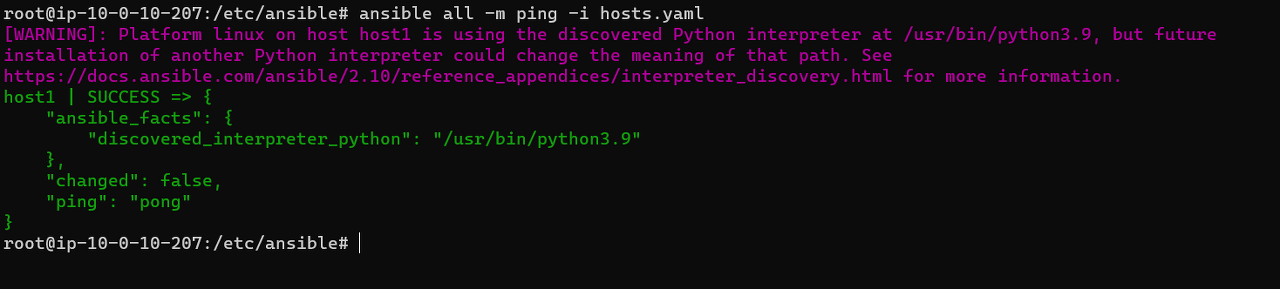
똑같이 잘 작동하는 것을 확인할 수 있다.

놀랍게도 위와 같이 별칭이 아닌 host ip로 적어주고 ansible_host 변수 없이도 정상 작동한다.
💡 인벤토리 변수끼리 우선순위를 정할 땐 그룹 변수보다 호스트 변수가 우선순위가 높다
그룹 변수는 그룹 안의 호스트 들에게 일괄 적용되는 세부 내용을 적용해주는 변수들이다. 아래의 형식으로 작성하게 된다.
webservser:
hosts:
host1:
host2:
vars:
[매개변수] : [값]

앞전의 코드를 그룹 변수 형태로 변경한 후 실행해 보겠다.

상위 그룹의 변수를 하위 그룹에 상속시킬 수 있다. 해당 내용은 Ansible Child Group에 대한 고찰에 서술하겠다. 또, 변수를 같은 인벤토리 파일에 작성하는 것이 아닌 외부 파일에 작성하고 호출할 수 있다.
Ansible은 인벤토리 파일이나 플레이북 파일을 이용하여 관련 경로를 검색하며 이런 호스트 및 그룹 변수 파일은 yaml 구문을 이용해야 한다. 이들의 변수 파일 또는 디렉토리는 아래와 같이 구성된다. 인벤토리 파일에 직접 변수를 적는 것보다 더 효율적인 관리가 가능하다.
/etc/ansible/group_vars/[그룹명]
/etc/ansible/host_vars/[호스트명]

인벤토리 파일의 변수를 주석시킨다.

디렉토리에 all 그룹의 변수를 적어준다.
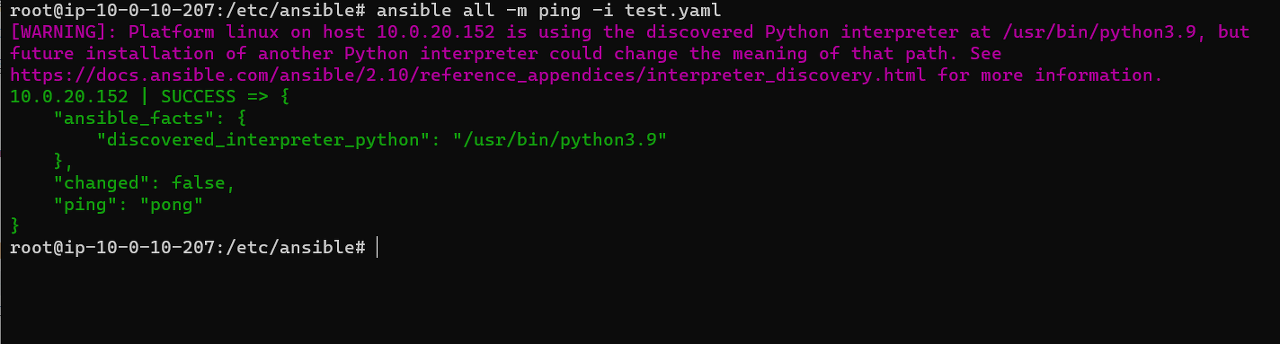
앞전과 동일하게 잘 실행되는 것을 확인할 수 있다.
더 좋은 가독성을 위해 변수들을 용도에 맞게 파일별로 정리해도 된다.
/etc/ansible/group_vars/[그룹명]/cluster_settings
/etc/ansible/group_vars/[그룹명]/db_settings
위와 같은 형식으로도 정리할 수 있다. Ansible은 이렇게 여러 파일이 정의되어 있다면 사전순으로 파일을 읽으며 변수를 적용한다.
동적 인벤토리
가상화, 클라우드 환경에서는 계속해서 동적으로 늘어나고 줄어드는 인스턴스들을 인벤토리 파일로 관리하기 힘들기 때문에 클라우드 공급자, LDAP, CDMB 등 동적 외부 인벤토리 시스템에서 호스트의 목록을 동적으로 가져올 수 있다.
인벤토리 플러그인, 인벤토리 스크립트 두 방식으로 구성할 수 있다. 이 두 방식 중에서는 플러그인 방식이 더 선호된다고 한다. 일단 동적 인벤토리 방식으로 AWS에 연결하려면 awscli를 설치하고 엑세스 키를 가진 유저가 필요하다. 여기에서는 서술하지 않겠다.
AWS와 연결되는 동적 인벤토리는 지켜줘야할 사항이 있는데 파일 형식이 **aws_ec2.yaml** 형식으로 끝나야 한다. 예를 들어 dynamic_aws_ec2.yaml, demo.aws_ec2.yaml 의 형식이다. 이를 지키지 않으면 AWS가 요청을 인식하지 못한다.
pip install boto3
또, AWS 플러그인을 지원하는 boto3 라이브러리를 설치해야한다.
plugin: aws_ec2
aws_access_key: [your access key]
aws_secret_key: [your secet key]
region:
- us-east-1
기초 형식은 위와 같다. access_key와 secret_key는 ansible.cfg에 환경변수로 지정해줘도 되는 것 같다. 파일에 적혀있지 않더라도 AWS CLI에 대해 유저를 등록해놓았다면 AWS CLI 자격증명으로 대체되어 요청이 전달된다.

확인을 위해 인벤토리 파일의 키 정보를 지우고 요청을 보낸다. ansible-inventory -i [파일명] --graph 명령어로 불러와지는 동적 인벤토리 값을 확인할 수 있다.

키 정보가 존재하지 않는데도 요청에 대한 응답이 반환된다.
#inventory 파일
aws_profile: default
or
boto3_profile: default
or
#환경변수 파일
AWS_PROFILE='profile_name'
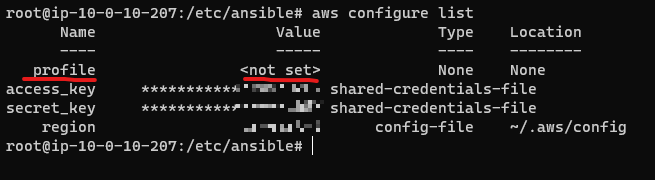
또는 키 정보를 입력하는 것이 아닌 AWS CLI 정보를 “profile” 로 지정할 수 있는데 이를 이용하여 구성할 수 있다.
그럼 동적 인벤토리를 이용하면 호스트의 그룹화는 어떻게 정의할까? Ansible 부분에서 꽤나 정통하신 gpt 선생 왈
- 인스턴스의 TAG
- 인스턴스의 속성(VPC ID, 보안 그룹)
- 서비스 또는 역할 기반
등으로 구분할 수 있다. 아래는 aws_ec2 플러그인의 매개변수들을 정리한다.
| 매개변수 | 설명 |
| keyed_groups | 접두사와 키 형식으로 제공되는 옵션에 맞는 인스턴스를 기준으로 분류한다. |
| groups | 그룹을 직접 지정하여 생성한다. |
| filters | EC2 인스턴스의 상태에 따라 구분하기 위해 존재한다. |
| compose | 조화된 인스턴스들을 접근하기 위한 호스트 설정을 구성 |
다양한 매개변수가 존재하는데 자세한 내용은 **해당 링크**에서 확인하도록 하는게 좋을 것 같다. 하나하나 보기 머리 아프다,,,또 이 링크에서 좀 더 자세하게 볼 수 있다.
hostnames
앞에서 말했듯이 그룹화를 하는 기준을 주는 매개변수라기 보단 그룹화되어 출력되는 호스트들의 명칭을 정하는 매개변수이다.
- ip-address #공인 ip로 나타냄
- dns-name #dns 이름으로 나타냄
- tag:Name # 인스턴스 이름으로 나타냄
- private-ip-address # 사설 ip로 나타냄

위와 같이 적어주고 실행해보겠다.
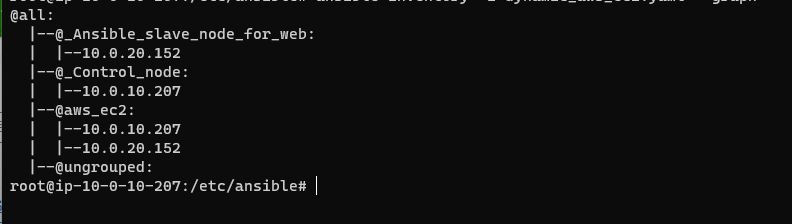
위와 같이 분류된 호스트들이 사설 ip로 나타나는 것을 확인할 수 있다. 이런 변수를 다른 속성과 연결해 표현할 수 있다.
- name: '뒤에 들어갈 속성'
separator: '-' # 말 그대로 분리자 공백마다 들어갈 문자 기본적으로 - 임
prefix: '앞에 들어갈 속성'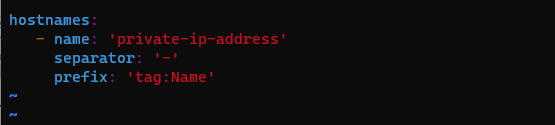
이렇게 작성하면 tag:Name 으로 나타나는 호스트 이름 뒤에 사설 ip를 붙이는 구문이다.
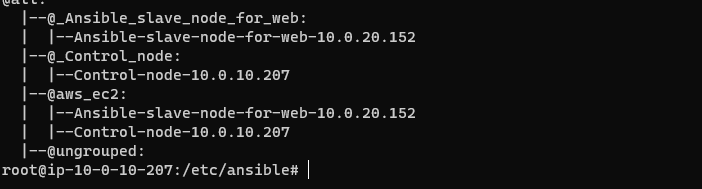
이렇게 호스트의 이름과 사설 IP까지 한번에 알 수 있다. 사실 hostnames 매개변수를 이용하지 않으면 굉장히 더럽게 나오니 가독성을 위해 이용하는게 좋을 것 같다.
keyed_groups
가장 중요한 매개변수 중 하나로 호스트들을 조건에 맞게 그룹화하는 변수이다. 또한, prefix와 key 값을 이용하여 나눠진 그룹의 이름을 부여한다.
Keyed_groups:
- prefix: tag
key: tags.Name
parent_group: "group name" # 이 변수에 들어가는 그룹의 하위 그룹으로 적용한다
위 코드는 기본적으로 다양한 분류 방식을 지원하지만 간단하게 인스턴스의 이름으로 구분하는 코드다. prefix 구문은 꼭 필요하진 않다. prefix 구문은 키와 연결되어 정해지는 호스트 그룹의 이름이다. 그렇다면 이용할 수 있는 KEY 값은 무엇이 있을까?
| key | 설명 |
| architacture | 인스턴스의 아키텍쳐를 기준으로 그룹화한다 |
| placement.availability_zone | 가용영역을 기준으로 그룹화한다. |
| tags | 인스턴스들의 키 값을 기준으로 그룹화한다. 이용할 태그를 tags.[’tag’] 또는 tags.tag 형식으로 적어주면 되는 것 같다. |
| instance_type | 인스턴스들의 타입 e.g. t2.micro |
| placement.region | 인스턴스들이 존재하는 리젼을 기준으로 그룹화한다 |
| 'security_groups | json_query("[].group_id")' |
| ansible_distribution | 이 변수는 ansible facts의 변수인데 해당 노드들의 OS 정보를 가져오므로 OS 별로 구분하게 된다. |
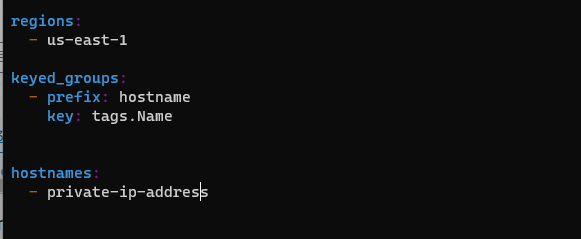
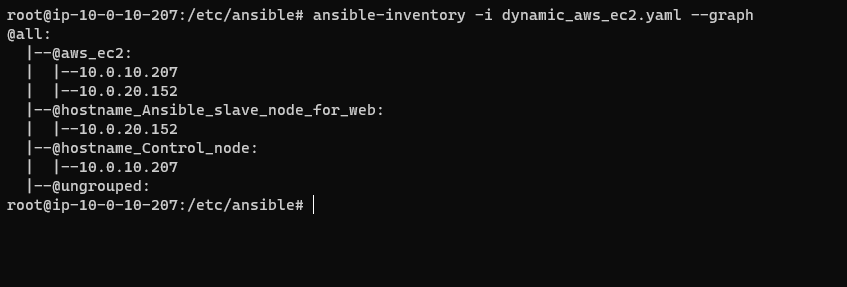
위 hostnames과 연계하여 가독성 있게 출력할 수 있다.

위 —list 옵션을 통해서 가독성은 떨어져도 인벤토리 내용에 대해 더 다양한 값을 불러올 수 있다.

이 명령어를 통해서 더 자세히 알 수 있는데 prefix+key 값으로 그룹이름이 정해지는 것을 확인할 수 있다. 이 때 동적 인벤토리 상에서 그룹 변수를 지정해주고 싶다면 같은 인벤토리 파일이 아닌 외부 파일을 이용해야하는 것 같다.

동적 인벤토리로 불러오는 그룹마다 유저가 달라 설정에 어려움을 겪고 있었는데 외부 파일로 적어주면 바로 해결될 줄 몰랐다. 또는 더욱 간단하게 playbook에 그룹마다 변수를 적어주면 해결된다.

정상 작동하는 것을 확인할 수 있다.
filters
이 매개변수는 인스턴스의 상태를 조건으로 그룹화되는 인스턴스들을 필터링할 수 있다.
| instance.group-id | 보안 그룹에 맞는 인스턴스만 불러온다 |
| instance-state-name | 상태에 맞는 인스턴스만 출력한다. |
| tag:[tag 변수]:[실제 tag] | 해당 tag를 가진 것만 출력한다 |

instance-state-name 변수를 running으로 추가하고 코드를 실행한다.

실제 인스턴스는 3개지만 실행 중인 인스턴스들만 출력되는 것을 확인할 수 있다.
tag에 대한 내용이 약간 헷가릴텐데 불러오는 tag를 세부지정 해준다고 생각하면 쉽다.
tag:Name: Control-node
#단일 지정
tag:Name:
- [name]
- [name]
#여러 개 지정
아래와 같이 지정한다면 Name tag 중에 Control-node를 가진 인스턴스만 출력한다는 뜻이다.
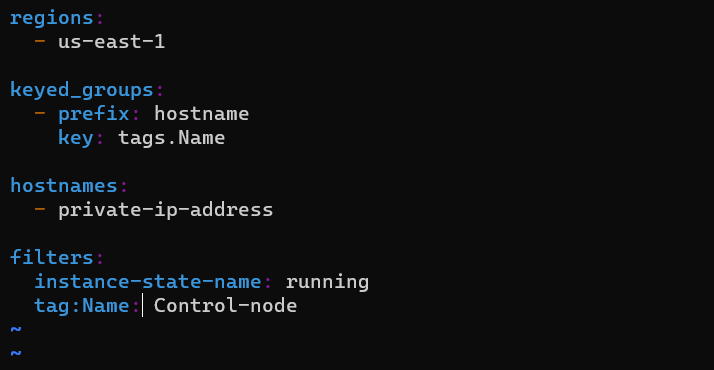
위와 같이 코드를 수정한다.
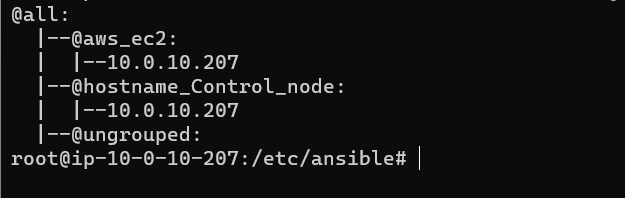
이론과 동일하게 Control_node만 출략되는 것을 확인할 수 있다.
compose
jinja2 문법을 이용하여 호스트 변수를 조정한다. jinja2 문법을 잘 모르기도 하고 아직 사용법과 사용 이유를 잘 모르겠어서 작성 안한다.
ansible ad-hoc과 playbook
AD-hoc command는 playbook 을 작성하지 않고 command-line에서 직접 엔서블 모듈을 호출해서 실행하는 방식으로 playbook과 다르게 단일작업을 수행한다.
ansible [호스트 패턴] -m [module] -a [module option] -i [inventory file]
ansible ad-hoc 명령어 형식은 위와 같다. ad-hoc에서 가장 많이 사용하는 모듈은 ping 모듈과 setup 모듈이다.
ping 모듈은 TCP의 ping이 아닌 대상 호스트의 python 모듈 실행 여부를 알 수 있는 모듈이다. setup 모듈은 **ansible facts**를 수집하는 모듈로 실행하게 되면 대상 호스트의 모든 정보를 출력한다. ansible facts에 대해서는 외부 페이지에 기고하겠다.
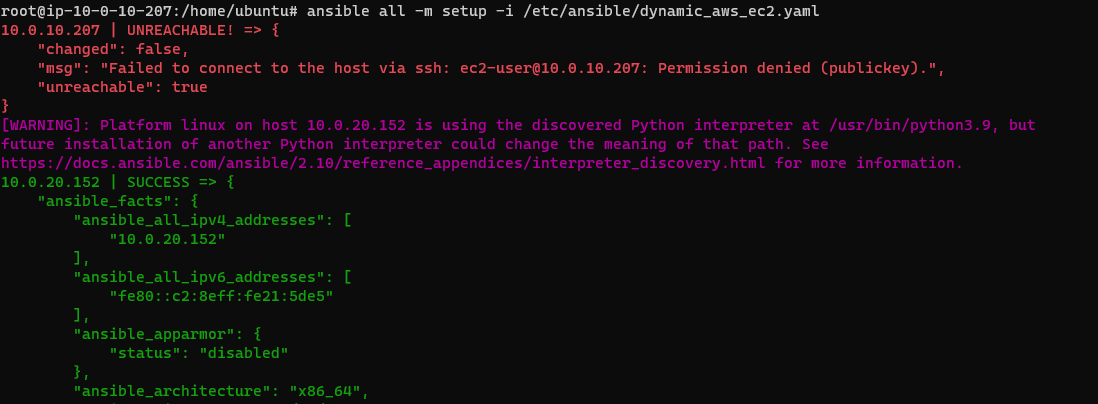
위는 setup 모듈을 실행한 모습이다. 너무 많은 정보가 출력되기 때문에 setup 모듈의 filter를 이용하여 보고 싶은 정보만 볼 수 있다.
playbook은 ad-hoc 명령을 yaml 형식의 스크립트로 만든 것이다(무조건 yaml 파일을 이용해야 한다). play 는 지정된 작업(task)을 모은 집합을 지칭하며 playbook은 1개 이상의 play를 모은 파일이다. playbook 안에서 play는 순서대로 실행된다.
playbook의 기본 구조, 즉 하나의 play는 name, hosts, tasks 이렇게 3가지 기본적인 요소로 구성되어 있다.
name은 play의 용도를 알려주며 필수 옵션은 아니다. playbook의 실행결과와 함께 출력되므로 주로 해당 play, task 등의 설명을 적는다.
hosts 플레이의 작업을 실행할 대상 호스트를 지정한다. 이 속성은 관리 호스트 또는 그룹의 이름을 값으로 사용한다.
tasks 실질적인 명령어들이 들어가는 가장 핵심적인 부분이다. tasks에 실행할 명령어, 이용할 모듈들이 명시된다.
---
- name : explain how to use
hosts: all
tasks:
- name:
[module]:

앞에서 계속 해왔던 ping 모듈을 playbook 형식으로 적어보도록 하겠다.

출력 형식은 다르지만 정상적으로 처리되는 것을 확인할 수 있다.
playbook 실행 명령어는 아래와 같다.
ansible-playbook [playbook file] -i [inventory file]
playbook 파일에 오류가 발생할 수 있다. 이 때 문제를 확인할 수 있는 방법이 두 가지가 있다.
실행하기 전 구문오류 체크 방법
ansible-playbook --syntax-check [playbook file]

파일 문법에 오류가 없다면 위와 같은 형식이 나타난다.
실행 시 verbose 모드를 사용하여 더 자세하게 결과를 확인
ansible-playbook -v [playbook file] -i [inventory file]
| -v | 작업 결과 표시 |
| -vv | 작업 결과와 작업 구성이 모두 표시 |
| -vvv | 관리 호스트 연결에 대한 정보를 포함 |
| -vvvv | 스크립트를 실행하기 위해 관리 호스트에서 사용 중인 사용자 및 실행된 스크립트를 포함하여 추가적인 플러그인 옵션을 연결 플로그인에 추가 |
playbook을 작성할 때 host-pattern을 지정하는 것이 중요하다. 아래의 표 대로 작성할 수 있으며 간단한 예를 보여주겠다.
| 설명 | 패턴 |
| 모든 호스트 | all 또는 * |
| 단일 호스트 | host1 |
| 여러 호스트 | host1:host2 또는 host1,host2 |
| 단일 그룹 | webservers |
| 여러 그룹 | webservers:dbservers |
| 제외 그룹 | webservers:!west |
| 교차 그룹 | webservers:&east |
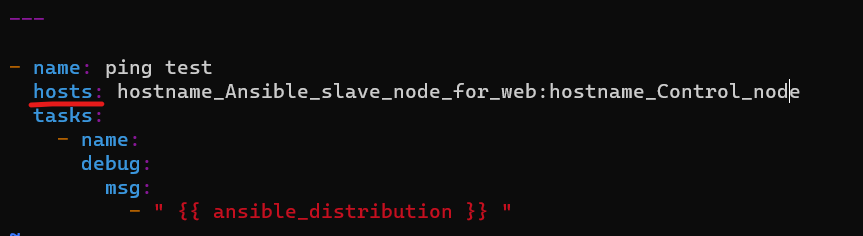
playbook의 호스트 패턴을 all 에서 따로 그룹 지정으로 실행해보도록 하겠다.
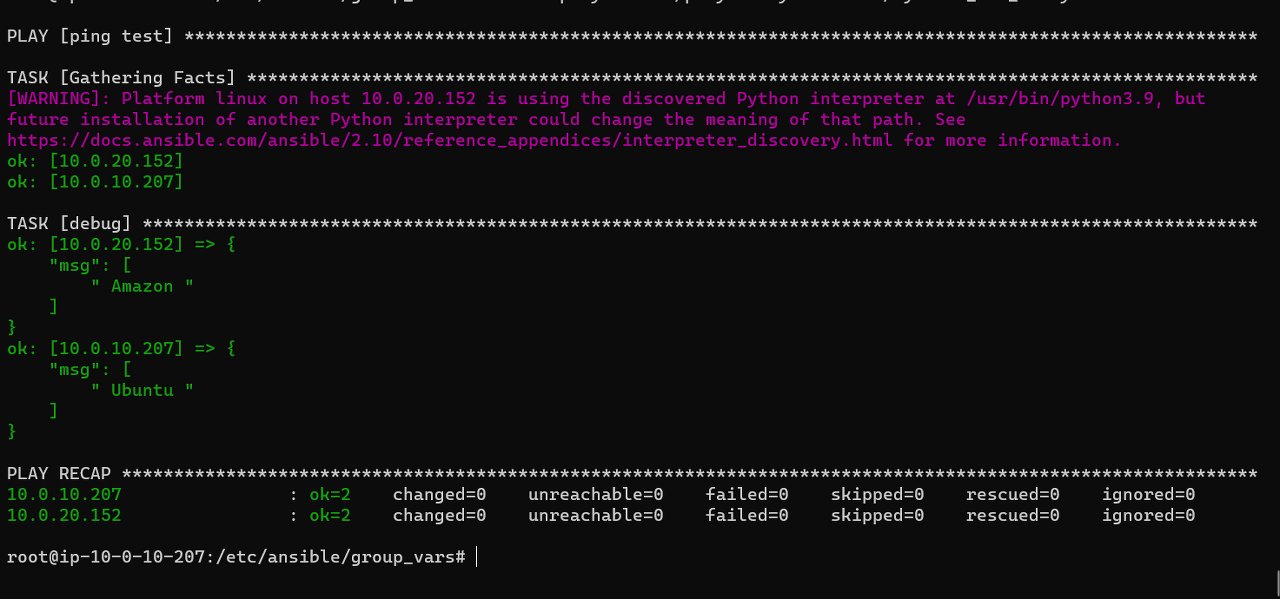
정상적으로 같은 결과를 내면서 실행되는 것을 확인할 수 있다.
변수 추가에서는 인벤토리 파일에 대한 변수를 다뤘다면 playbook에도 변수를 추가할 수 있다. 변수의 우선순위는 명령줄 > playbook > inventory 순으로 적용된다.
---
- name:
hosts:
vars:
[변수]
[변수]
playbook에서는 vars 키워드를 이용하여 변수 설정을 하게된다. 또, 인벤토리 처럼 파일에 따로 변수를 설정할 수도 있는데 vars_files 키워드로 구성한다.
--
- name:
hosts:
vars_files:
- [변수 파일 디렉토리]

위와 같이 작성

정상 작동한다. 근데 한 play 마다 gather fact를 실행하는걸로 보아서 인벤토리 변수에 한번에 적는게 더 효율적일 것 같다.
이제 이 이상의 Ansible facts 얘기나 각종 모듈들에 대한 얘기는 다른 글에서 작성하도록 하겠다.
'네트워크 > 네트워크 가상화, 자동화' 카테고리의 다른 글
| Anycast Gateway (1) | 2024.04.29 |
|---|---|
| Ansible Tags (2) | 2023.10.10 |
| Ansible facts (0) | 2023.09.13 |
| Ansible known hosts 자동 등록 & 무시 방법 (0) | 2023.09.12 |
💡 Ansible은 yaml 형식뿐만 아니라 ini 파일 형식도 지원한다. 대부분 인벤토리 파일은 ini 방식, playbook은 yaml 형식으로 작성하는 것 같으나 이 글은 일관성을 위해 뚝심있게 yaml 형식 위주로 작성된다.
💡 Ansible은 파이썬으로 개발되었기에 파이썬 모듈들을 통해서 대상 노드들과 통신한다. 따라서 Ansible을 깔면서 파이썬도 같이 깔아줘야한다.
이 글은 ansible의 기초 이론을 대충 이해하고 있다는 가정하에 실습 위주로 작성된다.
환경변수
먼저 ansible 환경변수 파일부터 알아보도록 하겠다.
apt install ansibleansible 엔진은 ansible 명령을 실행할 때 모든 환경 설정 및 세팅이 들어있는 ansible.cfg 환경변수 파일을 참고하여 명령을 실행한다. ansible 동작을 제어하는 환경변수 파일은 경로 상관 없이 ansible.cfg 파일에 구성되어야 한다.
ansible --version 명령어로 첫 확인 시 config file = none 에서 구성 후 디렉토리가 할당된 것을 확인할 수 있다.
구성 파일의 구성 내용도 설정 방식에 따라 우선순위가 존재하는데 아래와 같다
- ANSIBLE_CONFIG 환경변수
- 현재 디렉토리의 ansible.cfg
- 홈 디렉토리의 ~/.ansible.cfg
- /etc/ansible/ansible.cfg
ansible-config --view 명령어로 config file의 구성 상태를 볼 수 있다.
[defaults]
inventory = [인벤토리 경로]
remote_user = [ssh user]
ask_pass = [true/false]
private_key_file = /path/to/your/ssh/private/key
다시 ansible.cfg 파일로 돌아와서 inventory는 인벤토리의 경로 작성, remote_user는 Ansible이 ssh를 통해 통신할 때 이용할 유저 설정 항목, ask_pass는 접속 시 비밀번호를 물어볼 것인지 아닌지에 대한 설정 항목이다.
[defaults]는 ansible의 기본 설정을 정의하는 섹션인데 이외에도 여러 섹션이 존재한다. [inventory], [privilege_escalation], [ssh_connection] 등이 존재한는데 많이 사용되는 것은 [defaults], [privilege_escalation] 이다.
[pivilege_escalation]
become = [권한 상승 여부 -> 기본 false]
become_method = [권한 상승 방법 -> 기본 sudo]
become_user = [권한 상승할 사용자 -> 기본 root]
become_ask_pass = [권한 상승 방법의 패스워드 요청/입력 여부 -> false]
구성 후 간단한 ping 모듈을 통해 통신 시 구성 파일의 정보를 이용하여 통신에 성공하는 것을 확인할 수 있다. 여기서 의문점은 config file을 통해 범용적으로 사용되는 일반 설정을 구성했다면 remote_user가 구성 파일과 다른 노드는 어떻게 관리하지? 이는 인벤토리에서 처리해주게 된다. 이 글을 처음 쓸 때 inventory, config file 순으로 작성하였지만 여기에는 config file, inventory 순으로 작성하여 이해가 안되는 부분이 있을 수 있다. 아래 inventory 글을 보다 보면 이해할 수 있을 것이다.
inventory
💡 /etc/ansible/hosts 기본 파일은 ini 형식의 파일인 것 같다.
ansible이 관리하는 서버의 정보를 담은 파일을 인벤토리 파일이라고 한다. INI 방식 또는 yaml 방식으로 작성되며 기본적으로 /etc/ansible/hosts 파일을 이용하고 다른 파일을 불러오고 싶을 때에는 -i 옵션을 이용한다(여러 파일을 동시에 지정하거나 클라우드, 또는 CMDB에 저장된 내용도 불러올 수 있다). 이 외에도 인벤토리는 세가지 방법으로 지정 가능하다.
기본 설정 파일(/etc/ansible/hosts)에 설정
mkdir /etc/ansible/
vi /etc/ansible/hosts
all:
hosts:
~~~~:
#ini 형식에서는 all을 생략하니까
echo "192.168.10.1" > /etc/ansible/hosts
ANSIBLE_INVENTORY 환경 변수에 설정
vi ~/.ansible/hosts
test_group:
hosts:
~~~:
export ANSIBLE_INVENTORY=~/.ansible/hosts
외부 파일 작성 후 -i 옵션으로 명령어 실행 시 파일 경로 지정
ansible all -m ping -k -i ~/my_ansible_hosts
적용 우선 순위는 3 → 1 순이며 같은 노드가 여러 방식으로 지정되어 있다면 우선 순위가 높은 항목만 task(작업)이 적용된다. 1번 방식은 root 권한이 필요하며 유연성이 떨어져 잘 사용하지 않는다고 한다.
인벤토리에 각각의 호스트를 그룹 지어 정의할 수 있는데 모든 호스트는 하나 이상의 그룹에 속할 수 있다. 이 때 all과 ungrouped는 기본 그룹이다. 이 둘은 항상 존재하지만 명시적이라 실제 파일에 존재하지 않을 수 있다.
| all | ungrouped |
| 그룹에 속해 있는 모든 호스트 포함 | all 에 포함되지 않는 모든 호스트 |
#INI 형식
#YAML 형식과 다르게 ALL 구문 생략
[그룹명]
{IP}
{도메인}
EX)
[BRANCH]
192.168.10.2
www.brach.com
#yaml 형식
all:
hosts:
www.example.com:
192.168.10.21:
[그룹명]:
hosts:
[도메인]:
[IP]:
기본 구성 방식은 위와 같으며 만약 대상 노드의 서비스의 포트 번호가 다르다 [www.example.com:80](<http://www.example.com:80>) 또는, 인벤토리의 변수 선언으로도 지정이 가능하다.
하나의 호스트를 여러 그룹에 중복할당하는 것도 가능하다.
Ansible 공식 문서에서는 거의 기정 사실화로 이 기능을 사용할 것이라고 말하고 있다. Ansible 공식 문서에서는 무엇(애플리케이션, 스택 또는 마이크로서비스), 위치(로컬 DNS, 데이터센터나 배포 지역), 시기(배포판인지 테스트판이지 등등)의 3가지 기준으로 나누는 것을 권장한다.
all:
hosts:
www.idiot.com:
children:
webservers:
hosts:
ns.idiot.com:
east:
hosts:
ns.idiot.com:
위와 같이 중복하여 여러 그룹에 속하게 할 수 있다.
all:
hosts:
www.idiot.com:
children:
webservers:
hosts:
ns.idiot.com:
east:
children:
webservers:
위는 이전의 코드와 동일한 결과를 얻는 다른 코드이다. east에 webservers의 hosts의 내용을 중복 적용하는 것이 아닌 children 키워드를 통해서 그룹을 불러와 과정을 단순화할 수 있다.
또, 비슷한 이름의 호스트가 여러 개 존재한다면 모두 각각 추가하는 것이 아닌 알파벳이나 숫자로 범위를 지정하여 추가할 수 있다. 많이 사용되는지는 잘 모르겠다.
group1:
children:
host1-group:
hosts:
web[01:50].example.com:
host2-group:
hosts:
db-[a:f].example.com
위의 내용은 [01:50] 1부터 50까지라는 뜻으로 web1.example.com~web50.example.com을 한번에 추가한 것이다. 알파벳도 동일한 방식이다.
변수 추가
💡 PARAMIKO 연결 방식은 비SSH PORT(22번 이외의 포트)에 대한 연결에 오류를 일으킨다고 한다
ansible에는 호스트나 그룹에 대해 더 세부적인 정보를 구성할 수 있도록 다양한 변수를 지원하고 있다. 먼저 호스트 당 세부 내용을 적용할 수 있는 호스트 변수부터 알아볼 것인데 ini 형식과 yaml 형식 모두 파라미터는 같다.
아래의 파라미터는 기본적인 **연결 변수(ansible과 host 사이의 연결 방식을 정의하는 변수들)**들이다. 그룹 변수와 호스트 변수로 적용할 수 있는 여러 파라미터들이 존재하는데 이런 점은 배워가면서 정리해야할 것 같다.
| 매개변수 | 역할 |
| ansible_connection | 호스트의 연결 타입, local, smart, ssh, paramiko |
| ansible_host | 연결할 호스트의 도메인 또는 IP |
| ansible_port | SSH 포트 |
| ansible_user | SSH 유저 |
| ansible_ssh_pass | SSH 연결 시 사용할 비밀번호 |
| ansible_ssh_private_key_file | SSH 연결 시 사용할 키 파일 위치 |
| ansible_ssh_common_args | sftp, scp, ssh 와 같은 기본 명령을 사용할 때 항상 추가 설정 |
all:
hosts:
host1:
ansible_host: [ip]
ansible_ssh_private_key_file: [directory]
위와 같은 형식으로 적어준다. 위의 host1 은 다른 호스트들과 구분해주기 위한 구문으로 이 구문을 통해 별칭 지정도 가능하다. host1 → jumper로 변경 같이,,,
ansible.cfg에서 키 파일 위치를 주석 시킨다.
인벤토리 파일에 호스트 변수를 통해서 정보를 적어준다.
똑같이 잘 작동하는 것을 확인할 수 있다.
놀랍게도 위와 같이 별칭이 아닌 host ip로 적어주고 ansible_host 변수 없이도 정상 작동한다.
💡 인벤토리 변수끼리 우선순위를 정할 땐 그룹 변수보다 호스트 변수가 우선순위가 높다
그룹 변수는 그룹 안의 호스트 들에게 일괄 적용되는 세부 내용을 적용해주는 변수들이다. 아래의 형식으로 작성하게 된다.
webservser:
hosts:
host1:
host2:
vars:
[매개변수] : [값]
앞전의 코드를 그룹 변수 형태로 변경한 후 실행해 보겠다.
상위 그룹의 변수를 하위 그룹에 상속시킬 수 있다. 해당 내용은 Ansible Child Group에 대한 고찰에 서술하겠다. 또, 변수를 같은 인벤토리 파일에 작성하는 것이 아닌 외부 파일에 작성하고 호출할 수 있다.
Ansible은 인벤토리 파일이나 플레이북 파일을 이용하여 관련 경로를 검색하며 이런 호스트 및 그룹 변수 파일은 yaml 구문을 이용해야 한다. 이들의 변수 파일 또는 디렉토리는 아래와 같이 구성된다. 인벤토리 파일에 직접 변수를 적는 것보다 더 효율적인 관리가 가능하다.
/etc/ansible/group_vars/[그룹명]
/etc/ansible/host_vars/[호스트명]
인벤토리 파일의 변수를 주석시킨다.
디렉토리에 all 그룹의 변수를 적어준다.
앞전과 동일하게 잘 실행되는 것을 확인할 수 있다.
더 좋은 가독성을 위해 변수들을 용도에 맞게 파일별로 정리해도 된다.
/etc/ansible/group_vars/[그룹명]/cluster_settings
/etc/ansible/group_vars/[그룹명]/db_settings
위와 같은 형식으로도 정리할 수 있다. Ansible은 이렇게 여러 파일이 정의되어 있다면 사전순으로 파일을 읽으며 변수를 적용한다.
동적 인벤토리
가상화, 클라우드 환경에서는 계속해서 동적으로 늘어나고 줄어드는 인스턴스들을 인벤토리 파일로 관리하기 힘들기 때문에 클라우드 공급자, LDAP, CDMB 등 동적 외부 인벤토리 시스템에서 호스트의 목록을 동적으로 가져올 수 있다.
인벤토리 플러그인, 인벤토리 스크립트 두 방식으로 구성할 수 있다. 이 두 방식 중에서는 플러그인 방식이 더 선호된다고 한다. 일단 동적 인벤토리 방식으로 AWS에 연결하려면 awscli를 설치하고 엑세스 키를 가진 유저가 필요하다. 여기에서는 서술하지 않겠다.
AWS와 연결되는 동적 인벤토리는 지켜줘야할 사항이 있는데 파일 형식이 **aws_ec2.yaml** 형식으로 끝나야 한다. 예를 들어 dynamic_aws_ec2.yaml, demo.aws_ec2.yaml 의 형식이다. 이를 지키지 않으면 AWS가 요청을 인식하지 못한다.
pip install boto3
또, AWS 플러그인을 지원하는 boto3 라이브러리를 설치해야한다.
plugin: aws_ec2
aws_access_key: [your access key]
aws_secret_key: [your secet key]
region:
- us-east-1
기초 형식은 위와 같다. access_key와 secret_key는 ansible.cfg에 환경변수로 지정해줘도 되는 것 같다. 파일에 적혀있지 않더라도 AWS CLI에 대해 유저를 등록해놓았다면 AWS CLI 자격증명으로 대체되어 요청이 전달된다.
확인을 위해 인벤토리 파일의 키 정보를 지우고 요청을 보낸다. ansible-inventory -i [파일명] --graph 명령어로 불러와지는 동적 인벤토리 값을 확인할 수 있다.
키 정보가 존재하지 않는데도 요청에 대한 응답이 반환된다.
#inventory 파일
aws_profile: default
or
boto3_profile: default
or
#환경변수 파일
AWS_PROFILE='profile_name'
또는 키 정보를 입력하는 것이 아닌 AWS CLI 정보를 “profile” 로 지정할 수 있는데 이를 이용하여 구성할 수 있다.
그럼 동적 인벤토리를 이용하면 호스트의 그룹화는 어떻게 정의할까? Ansible 부분에서 꽤나 정통하신 gpt 선생 왈
- 인스턴스의 TAG
- 인스턴스의 속성(VPC ID, 보안 그룹)
- 서비스 또는 역할 기반
등으로 구분할 수 있다. 아래는 aws_ec2 플러그인의 매개변수들을 정리한다.
| 매개변수 | 설명 |
| keyed_groups | 접두사와 키 형식으로 제공되는 옵션에 맞는 인스턴스를 기준으로 분류한다. |
| groups | 그룹을 직접 지정하여 생성한다. |
| filters | EC2 인스턴스의 상태에 따라 구분하기 위해 존재한다. |
| compose | 조화된 인스턴스들을 접근하기 위한 호스트 설정을 구성 |
다양한 매개변수가 존재하는데 자세한 내용은 **해당 링크**에서 확인하도록 하는게 좋을 것 같다. 하나하나 보기 머리 아프다,,,또 이 링크에서 좀 더 자세하게 볼 수 있다.
hostnames
앞에서 말했듯이 그룹화를 하는 기준을 주는 매개변수라기 보단 그룹화되어 출력되는 호스트들의 명칭을 정하는 매개변수이다.
- ip-address #공인 ip로 나타냄
- dns-name #dns 이름으로 나타냄
- tag:Name # 인스턴스 이름으로 나타냄
- private-ip-address # 사설 ip로 나타냄
위와 같이 적어주고 실행해보겠다.
위와 같이 분류된 호스트들이 사설 ip로 나타나는 것을 확인할 수 있다. 이런 변수를 다른 속성과 연결해 표현할 수 있다.
- name: '뒤에 들어갈 속성'
separator: '-' # 말 그대로 분리자 공백마다 들어갈 문자 기본적으로 - 임
prefix: '앞에 들어갈 속성'이렇게 작성하면 tag:Name 으로 나타나는 호스트 이름 뒤에 사설 ip를 붙이는 구문이다.
이렇게 호스트의 이름과 사설 IP까지 한번에 알 수 있다. 사실 hostnames 매개변수를 이용하지 않으면 굉장히 더럽게 나오니 가독성을 위해 이용하는게 좋을 것 같다.
keyed_groups
가장 중요한 매개변수 중 하나로 호스트들을 조건에 맞게 그룹화하는 변수이다. 또한, prefix와 key 값을 이용하여 나눠진 그룹의 이름을 부여한다.
Keyed_groups:
- prefix: tag
key: tags.Name
parent_group: "group name" # 이 변수에 들어가는 그룹의 하위 그룹으로 적용한다
위 코드는 기본적으로 다양한 분류 방식을 지원하지만 간단하게 인스턴스의 이름으로 구분하는 코드다. prefix 구문은 꼭 필요하진 않다. prefix 구문은 키와 연결되어 정해지는 호스트 그룹의 이름이다. 그렇다면 이용할 수 있는 KEY 값은 무엇이 있을까?
| key | 설명 |
| architacture | 인스턴스의 아키텍쳐를 기준으로 그룹화한다 |
| placement.availability_zone | 가용영역을 기준으로 그룹화한다. |
| tags | 인스턴스들의 키 값을 기준으로 그룹화한다. 이용할 태그를 tags.[’tag’] 또는 tags.tag 형식으로 적어주면 되는 것 같다. |
| instance_type | 인스턴스들의 타입 e.g. t2.micro |
| placement.region | 인스턴스들이 존재하는 리젼을 기준으로 그룹화한다 |
| 'security_groups | json_query("[].group_id")' |
| ansible_distribution | 이 변수는 ansible facts의 변수인데 해당 노드들의 OS 정보를 가져오므로 OS 별로 구분하게 된다. |
위 hostnames과 연계하여 가독성 있게 출력할 수 있다.
위 —list 옵션을 통해서 가독성은 떨어져도 인벤토리 내용에 대해 더 다양한 값을 불러올 수 있다.
이 명령어를 통해서 더 자세히 알 수 있는데 prefix+key 값으로 그룹이름이 정해지는 것을 확인할 수 있다. 이 때 동적 인벤토리 상에서 그룹 변수를 지정해주고 싶다면 같은 인벤토리 파일이 아닌 외부 파일을 이용해야하는 것 같다.
동적 인벤토리로 불러오는 그룹마다 유저가 달라 설정에 어려움을 겪고 있었는데 외부 파일로 적어주면 바로 해결될 줄 몰랐다. 또는 더욱 간단하게 playbook에 그룹마다 변수를 적어주면 해결된다.
정상 작동하는 것을 확인할 수 있다.
filters
이 매개변수는 인스턴스의 상태를 조건으로 그룹화되는 인스턴스들을 필터링할 수 있다.
| instance.group-id | 보안 그룹에 맞는 인스턴스만 불러온다 |
| instance-state-name | 상태에 맞는 인스턴스만 출력한다. |
| tag:[tag 변수]:[실제 tag] | 해당 tag를 가진 것만 출력한다 |
instance-state-name 변수를 running으로 추가하고 코드를 실행한다.
실제 인스턴스는 3개지만 실행 중인 인스턴스들만 출력되는 것을 확인할 수 있다.
tag에 대한 내용이 약간 헷가릴텐데 불러오는 tag를 세부지정 해준다고 생각하면 쉽다.
tag:Name: Control-node
#단일 지정
tag:Name:
- [name]
- [name]
#여러 개 지정
아래와 같이 지정한다면 Name tag 중에 Control-node를 가진 인스턴스만 출력한다는 뜻이다.
위와 같이 코드를 수정한다.
이론과 동일하게 Control_node만 출략되는 것을 확인할 수 있다.
compose
jinja2 문법을 이용하여 호스트 변수를 조정한다. jinja2 문법을 잘 모르기도 하고 아직 사용법과 사용 이유를 잘 모르겠어서 작성 안한다.
ansible ad-hoc과 playbook
AD-hoc command는 playbook 을 작성하지 않고 command-line에서 직접 엔서블 모듈을 호출해서 실행하는 방식으로 playbook과 다르게 단일작업을 수행한다.
ansible [호스트 패턴] -m [module] -a [module option] -i [inventory file]
ansible ad-hoc 명령어 형식은 위와 같다. ad-hoc에서 가장 많이 사용하는 모듈은 ping 모듈과 setup 모듈이다.
ping 모듈은 TCP의 ping이 아닌 대상 호스트의 python 모듈 실행 여부를 알 수 있는 모듈이다. setup 모듈은 **ansible facts**를 수집하는 모듈로 실행하게 되면 대상 호스트의 모든 정보를 출력한다. ansible facts에 대해서는 외부 페이지에 기고하겠다.
위는 setup 모듈을 실행한 모습이다. 너무 많은 정보가 출력되기 때문에 setup 모듈의 filter를 이용하여 보고 싶은 정보만 볼 수 있다.
playbook은 ad-hoc 명령을 yaml 형식의 스크립트로 만든 것이다(무조건 yaml 파일을 이용해야 한다). play 는 지정된 작업(task)을 모은 집합을 지칭하며 playbook은 1개 이상의 play를 모은 파일이다. playbook 안에서 play는 순서대로 실행된다.
playbook의 기본 구조, 즉 하나의 play는 name, hosts, tasks 이렇게 3가지 기본적인 요소로 구성되어 있다.
name은 play의 용도를 알려주며 필수 옵션은 아니다. playbook의 실행결과와 함께 출력되므로 주로 해당 play, task 등의 설명을 적는다.
hosts 플레이의 작업을 실행할 대상 호스트를 지정한다. 이 속성은 관리 호스트 또는 그룹의 이름을 값으로 사용한다.
tasks 실질적인 명령어들이 들어가는 가장 핵심적인 부분이다. tasks에 실행할 명령어, 이용할 모듈들이 명시된다.
---
- name : explain how to use
hosts: all
tasks:
- name:
[module]:
앞에서 계속 해왔던 ping 모듈을 playbook 형식으로 적어보도록 하겠다.
출력 형식은 다르지만 정상적으로 처리되는 것을 확인할 수 있다.
playbook 실행 명령어는 아래와 같다.
ansible-playbook [playbook file] -i [inventory file]
playbook 파일에 오류가 발생할 수 있다. 이 때 문제를 확인할 수 있는 방법이 두 가지가 있다.
실행하기 전 구문오류 체크 방법
ansible-playbook --syntax-check [playbook file]
파일 문법에 오류가 없다면 위와 같은 형식이 나타난다.
실행 시 verbose 모드를 사용하여 더 자세하게 결과를 확인
ansible-playbook -v [playbook file] -i [inventory file]
| -v | 작업 결과 표시 |
| -vv | 작업 결과와 작업 구성이 모두 표시 |
| -vvv | 관리 호스트 연결에 대한 정보를 포함 |
| -vvvv | 스크립트를 실행하기 위해 관리 호스트에서 사용 중인 사용자 및 실행된 스크립트를 포함하여 추가적인 플러그인 옵션을 연결 플로그인에 추가 |
playbook을 작성할 때 host-pattern을 지정하는 것이 중요하다. 아래의 표 대로 작성할 수 있으며 간단한 예를 보여주겠다.
| 설명 | 패턴 |
| 모든 호스트 | all 또는 * |
| 단일 호스트 | host1 |
| 여러 호스트 | host1:host2 또는 host1,host2 |
| 단일 그룹 | webservers |
| 여러 그룹 | webservers:dbservers |
| 제외 그룹 | webservers:!west |
| 교차 그룹 | webservers:&east |
playbook의 호스트 패턴을 all 에서 따로 그룹 지정으로 실행해보도록 하겠다.
정상적으로 같은 결과를 내면서 실행되는 것을 확인할 수 있다.
변수 추가에서는 인벤토리 파일에 대한 변수를 다뤘다면 playbook에도 변수를 추가할 수 있다. 변수의 우선순위는 명령줄 > playbook > inventory 순으로 적용된다.
---
- name:
hosts:
vars:
[변수]
[변수]
playbook에서는 vars 키워드를 이용하여 변수 설정을 하게된다. 또, 인벤토리 처럼 파일에 따로 변수를 설정할 수도 있는데 vars_files 키워드로 구성한다.
--
- name:
hosts:
vars_files:
- [변수 파일 디렉토리]
위와 같이 작성
정상 작동한다. 근데 한 play 마다 gather fact를 실행하는걸로 보아서 인벤토리 변수에 한번에 적는게 더 효율적일 것 같다.
이제 이 이상의 Ansible facts 얘기나 각종 모듈들에 대한 얘기는 다른 글에서 작성하도록 하겠다.
'네트워크 > 네트워크 가상화, 자동화' 카테고리의 다른 글
| Anycast Gateway (1) | 2024.04.29 |
|---|---|
| Ansible Tags (2) | 2023.10.10 |
| Ansible facts (0) | 2023.09.13 |
| Ansible known hosts 자동 등록 & 무시 방법 (0) | 2023.09.12 |