
네트워크 혼잡
QoS에 대해 알아보기 전 네트워크 혼잡에 대해 알아보아야 합니다. 네트워크 혼잡은 패킷의 손실, 지연 또는 새로운 연결 차단을 유발하는 현상을 뜻합니다. 대표적으로 지터를 생각해보시면 될 것 같습니다. 이런 네트워크 혼잡은 2가지 이유와 3가지 구조에서 발생합니다.
1. 빠른 인터페이스에서 느린 인터페이스로 포워딩할 시 발생
2. 큰 패킷이 작은 패킷의 포워딩을 지연시킬 시 발생
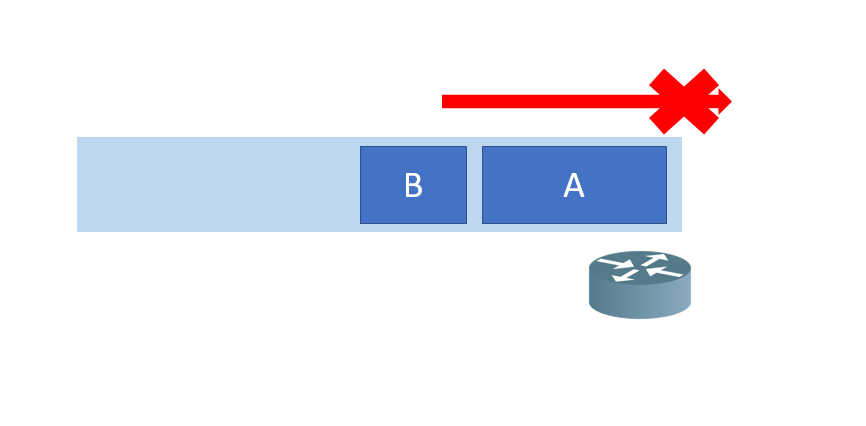
2번이 발생하는 이유를 조금 더 깊게 설명해보겠습니다. 라우터나 스위치같은 네트워크 장치는 전송될 수 있는 양의 트래픽보다 더 많은 트래픽이 들어올 때 자원이 확보될 때까지 큐에 패킷을 저장하고 대기시킵니다. 그 후 자원을 확보면 전송하게 됩니다. 이는 당연히 지연을 발생시키고요. QoS 솔루션이 없다고 할 때 더 큰 패킷이 큐에 적재되고 작은 패킷이 적재됐다면 작은 큐가 전송 가능하더라도 더 큰 패킷의 자원이 확보될 때까지 포워딩할 수 없습니다. 큐는 메모리에 할당되기 때문에 점점 패킷이 메모리에 쌓이게 되고 메모리 자원을 초과하게 되면 큐에 적재된 패킷을 삭제하게 됩니다. 이것이 바로 패킷 손실이 일어나는 이유 중 하나입니다.
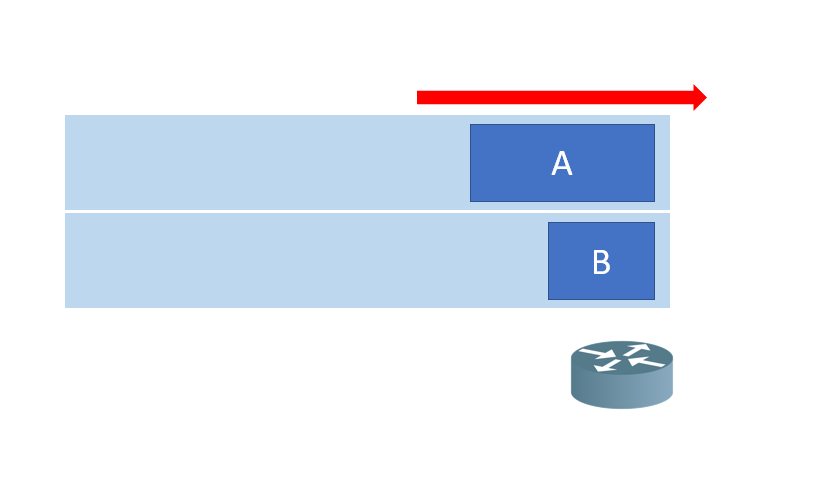
QoS는 트래픽에 우선순위를 부여하여 큐를 여러개로 구성하도록 하여 이를 해결합니다.

위의 사진은 네트워크 혼잡이 발생하는 지점입니다. 여러 트래픽이 하나의 인터페이스로 나가는 집합 지점과 처음 설명했던 ingress traffic과 egress traffic의 전송속도의 차이가 존재하는 지점에 인해 발생합니다.
네트워크 성능 지표
| 지표 | 설명 | |
| Bandwidth | 링크가 전송할 수 있는 양 | Banwidth != link speed |
| Delay | 송신자에서 수신자까지 패킷이 도착하는데 걸리는 시간 | |
| Loss | 패킷의 손실, 수신지에 도착하지 못하는 현상 | |
| Jitter | 패킷 사이의 지연 측정 값 |
QoS(Quality of Service)

QoS는 네트워크의 지터를 줄이고 품질 저하를 방지하여 데이터 트래픽을 관리하는 일련의 기술과 네트워크에서 전송되는 데이터의 우선 순위를 설정하여 품질 저하를 방지하는 기술입니다.

QoS 작업은 일반적으로 트래픽 분류 및 우선순위 표시(marking) → 혼잡회피(폴리싱과 드랍) → 큐잉 → 스케쥴링과 쉐이핑의 순서로 작동합니다.
트래픽 분류와 우선순위 표시
트래픽 분류는 특정 인터페이스에서 들어온 트래픽이나 ACL, 클래스 맵을 이용하여 트래픽을 분류하는 과정입니다. 패킷에 우선순위 표시를 통해 우선순위를 지정하면 장치가 이 우선순위에 맞는 클래스를 이용하여 트래픽을 분류하는 식인거죠.
우선순위는 2계층과 3계층에서 다르게 표시되는데 CoS와 IPP 또는 DSCP라는 것에 의해 결정됩니다.
Class of Service
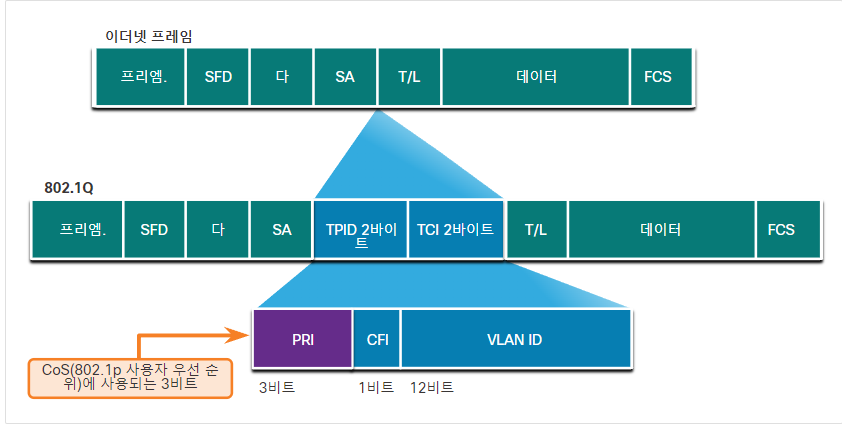
이더넷 프레임에는 공간이 없어 802.1Q의 헤더에 3비트를 이용하여 우선순위를 적어줍니다. 0~7에서의 8단계로 우선순위를 표시할 수 있습니다. (802.1P라고도 합니다)
IPP와 DSCP
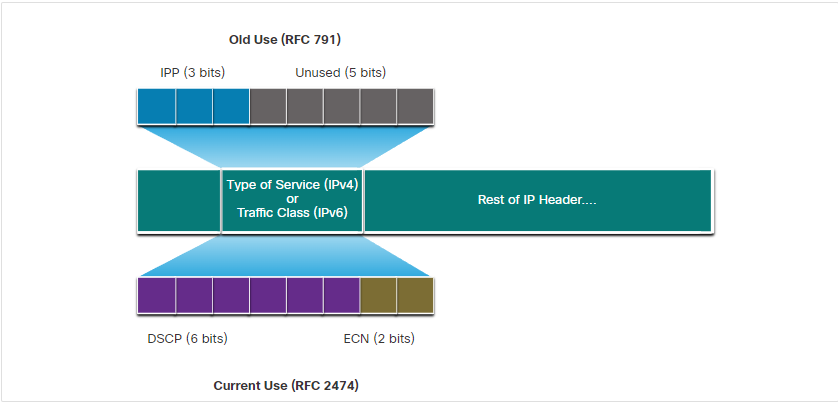
3계층에서는 ToS 필드에 3비트를 이용하여 패킷의 우선순위를 설정하게 됩니다. 이 과정을 IP Precedence라고 합니다. IPP는 3비트만 이용하여 8단계로만 우선순위를 지정할 수 밖에 없기 때문에 현재 네트워크에서 사용하기 힘듭니다. 따라서 우선순위 표기를 6비트로 늘려 더욱 세분화할 수 있도록한 것이 DSCP입니다. TOS 필드는 총 8비트인데 나머지 2비트는 DSCP에서 Explicit Congestion Notification 필드로 패킷에 혼잡이 있음을 알립니다. DSCP는 값에 따라 3가지의 범주로 분류됩니다.
Best-effort : DSCP 0으로 QoS가 설정되지 않은 상태입니다.
Expedited Forwarding : DSCP 값 46이며 일반적으로 음성 데이터에 설정됩니다. DSCP 46은 다른 어떤 트래픽보다 우선 권한을 가지게되며 우선순위 큐에 의해서 가장 빠르게 입출력됩니다. 이는 실시간성이 중요한 음성 데이터의 특성 때문에 그렇습니다. 음성 데이터의 경우 혼잡이 발생할 경우 뒤에 말한 내용이 수신자 입장에서 앞의 내용보다 먼저 들릴 수 있고 음성이 지직 거리거나 하는 문제로 통신에 불편을 겪을 수 있기 때문입니다.
Assured Forwarding : 46번을 제외한 DSCP 5개의 bit를 이용하여 큐와 패킷의 삭제에 대한 기본 설정을 나타낸 방식입니다.
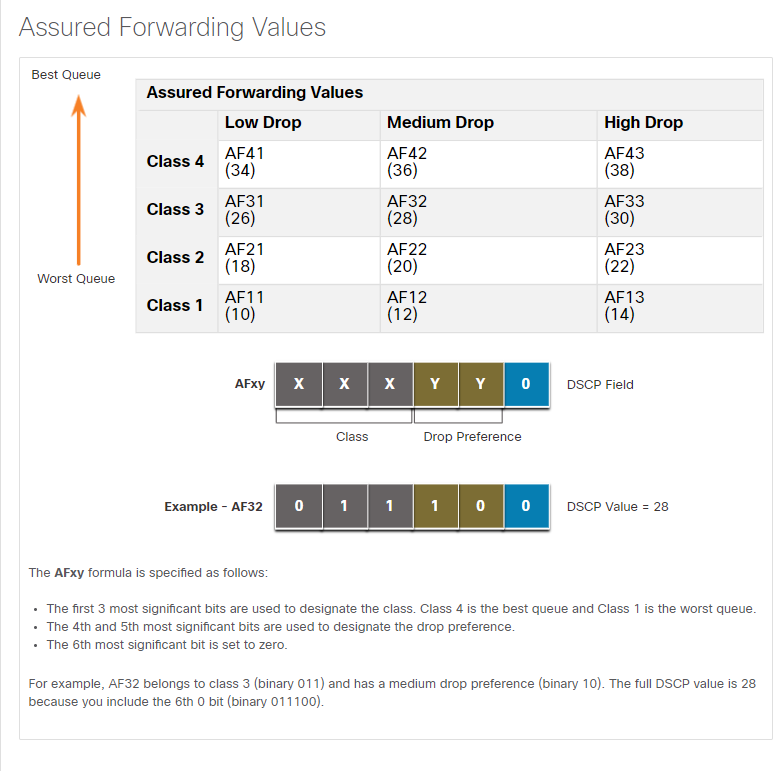
상위 비트 3개는 클래스를 지정하는데 사용되며 그 뒤의 2개 비트는 해당 트래픽에 대해 폐기할 때의 우선순위를 결정하게 됩니다. 이는 밑의 혼잡회피에서 더 깊게 다루도록 하겠습니다. 마지막 비트는 0으로 비어둡니다.
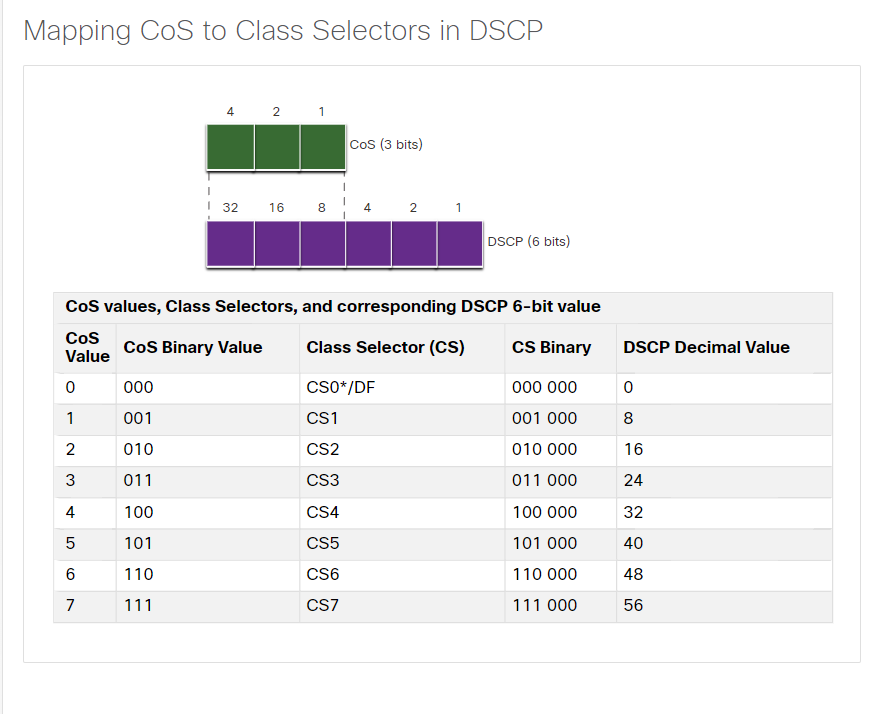
CoS와 DSCP,IPP는 매핑되며 매핑에 대한 계산법입니다.

트래픽에 대한 우선순위 표시는 트래픽이 발생하는 호스트와 가장 가까운 스위치나 라우터에 정책이 적용되어야 합니다. 라우터에 Class를 통해 관리자의 편의대로 트래픽에 대한 처리 정책을 설정하고 DSCP에 의해 우선순위가 표시된 패킷들이 라우터를 지날 때 Class로 정의된 정책에 의해 처리되는 방식인 것입니다.
Traffic Policing과 Traffic shaping
먼저 혼잡회피에 대해 얘기하기 전에 Traffic policng을 어디에서 수행해야 하는지 알아갈 필요가 있습니다. 간단하게 말하자면 LAN이 WAN보다 물리적으로 가까워 jitter나 delay가 덜 발생합니다. 또, LAN은 특정 기관에 의해 직접 관리되기 때문에 올바르게 구성되고 혼잡이 발생하도록 과잉 구성되지 않았다면 LAN보다 WAN이 이런 QoS와 관련된 사항에 민감할 수 밖에 없습니다. 따라서 WAN에 Traffic policing과 같은 혼잡회피 정책을 설정해주는 것이 올바릅니다.
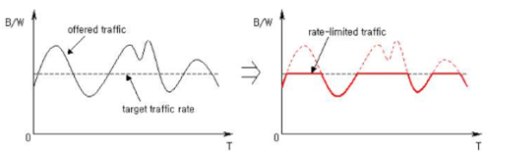
Traffic policing은 일정 비율에 맞는 패킷을 포워딩하면서 대역폭을 초과하는 패킷을 드랍하는 방식을 말합니다. 예를 들어 ISP는 100Byte의 속도를 제공하는 회선을 이용하지만 구매자는 10Byte의 속도만 이용하고 싶을 수 있습니다. 이런 때 Traffic policing을 사용할 수도 있습니다. 또는 보안을 위해 디도스로 생각되는 트래픽을 막도록 하는데 이용할 수 있습니다. 이를 구현하는데에는 여러 방식이 있지만 token bucket 방식을 통해 구현하는 방법으로 기술해보겠습니다.
| 용어 | 뜻 |
| CIR(Committed Information Rate) | ISP가 Client에게 할당하는 대역폭 EX) 100bps |
| AR(Aceess Rate) | 실제 회선을 통해 물리적으로 이용 가능한 대역폭 |
| BC(Committed Burst) | CIR을 넘지 않거나 혼잡을 발생시키지 않으면서 한번에 보낼 수 있는 패킷의 크기 |
본문으로 들어가기 전 위의 용어들을 알고 있으셔야 합니다. Token이라는 개념을 이용하는데 Token은 패킷을 보낼 수 있는 권한? 정도로 생각하시면 됩니다. 1Token은 1Byte를 말하고요.
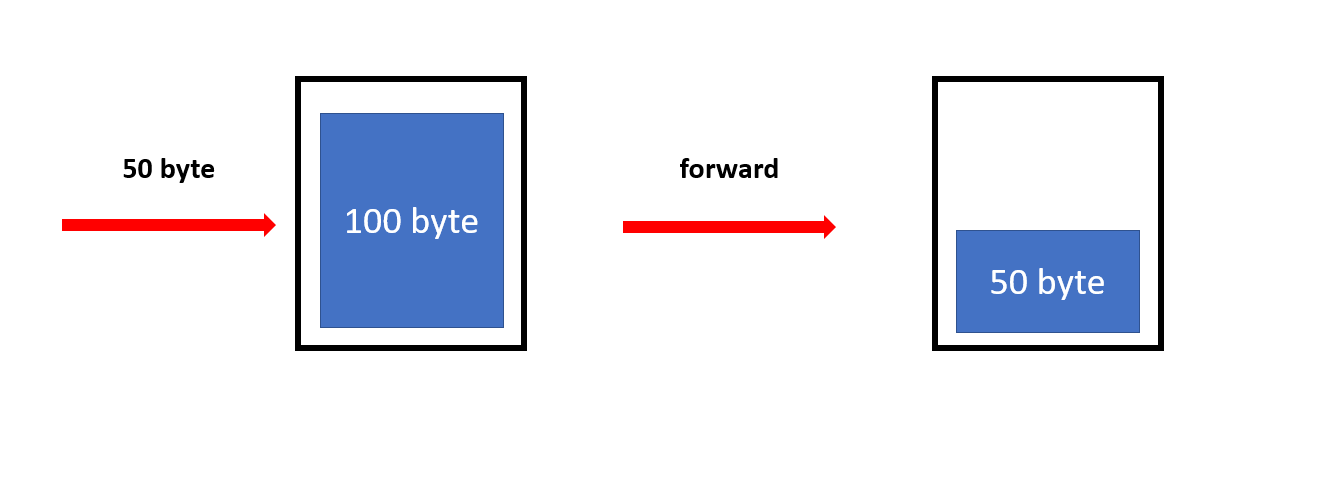
Bucket에 관리자가 설정한 일정량의 Token이 채워져 있습니다. 이 때 들어오는 패킷이 Token의 총 양으로 보낼 수 있는 크기의 패킷이라면 포워딩 하고 Token 양을 줄이는 것입니다.
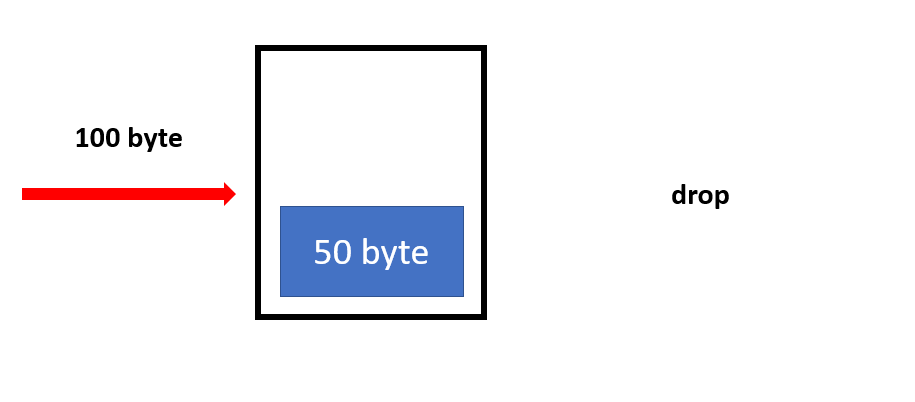
만약 충분한 양이 없다면 패킷을 드랍하는 방식으로 기본적인 절차는 이렇습니다. 당연히 버킷 안의 토큰이 줄어들기만 해서는 안되므로 다시 채워질 수 있습니다.
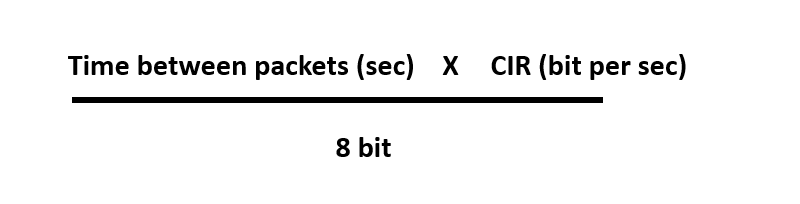
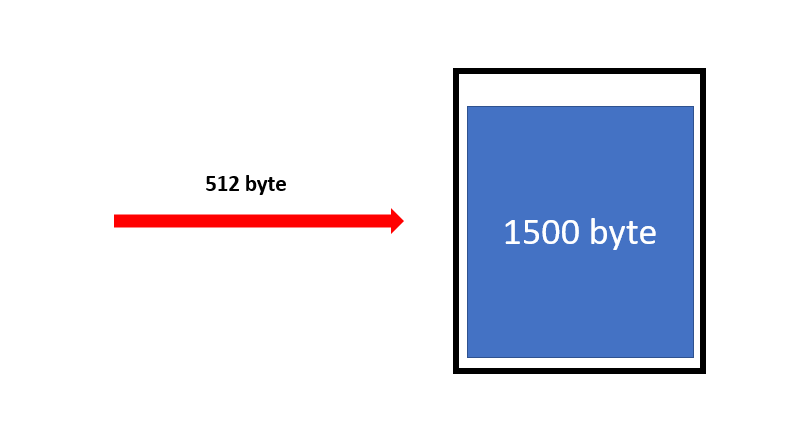
버켓에 토큰을 다시 채우는 수식은 위와 같습니다. 그래서 예를 들어 ISP가 Client에게 CIR은 16000bps를 Bc는 1500 bytes를 할당했다고 생각해봅시다. 처음 보내는 패킷은 512byte였다고 생각해보겠습니다. 처음 버켓은 그럼 Toekn 1500 byte를 가지고 생성됩니다.
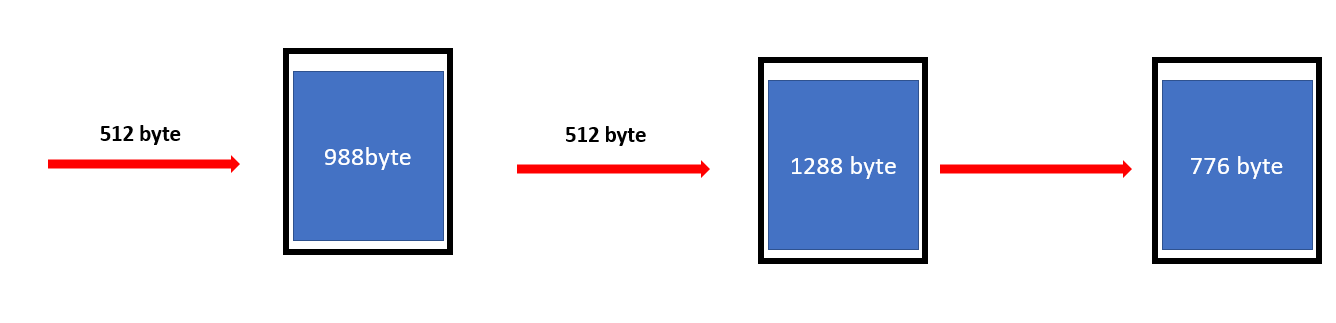
그럼 1차적으로 1500-512는 988이므로 토큰은 988 바이트가 남게 됩니다. 이 때 512 Byte의 패킷이 0.15 sec의 속도로 다시 들어왔다면 위의 수식을 통해 버켓에 토큰을 다시 채워넣게 됩니다. 위 수식대로라면 0.15 * 16000 / 8 == 300 이기 때문에 1288byte로 버켓이 다시 채워지고 이 과정을 반복하는 것입니다.
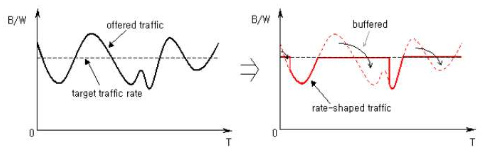
Traffic policing은 결과적으로 패킷을 삭제하면서 혼잡을 회피하는 기법이기 때문에 Traffic shaping은 다른 방식을 이용합니다. Traffic shaping은 패킷을 삭제하지 않고 버퍼를 생성하여 혼잡이 해결될 때 까지 이를 저장했다가 혼잡이 해결되고 나면 한번에 포워딩하는 방식으로 혼잡을 회피합니다. Traffic shaping의 절차도 똑같이 Token Bucket 방식을 통해 설명드리겠습니다. 약간의 폴리싱과 다른 점은 쉐이핑에서는 1 bit == 1 token입니다. (물론 트래픽 쉐이핑은 스케쥴링고 같이 가장 마지막에 일어나는 절차지만 둘이 비슷한 절차를 가지고 있어 함계 설명했습니다.)
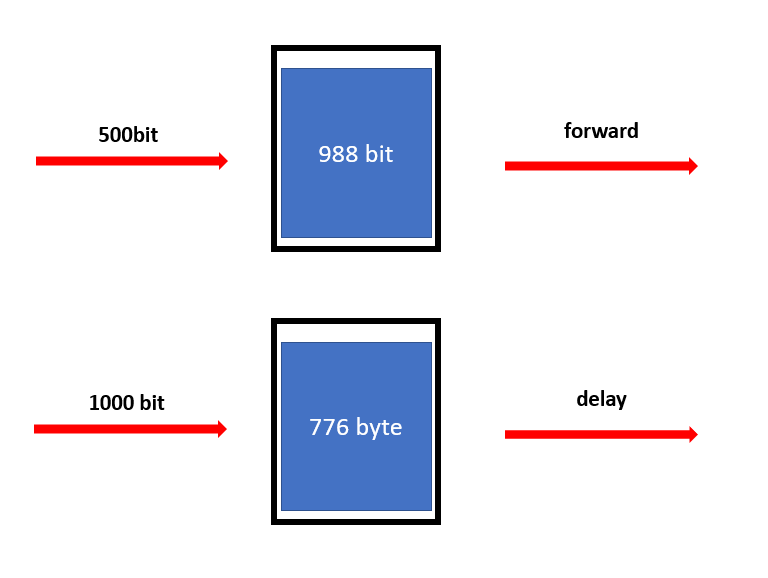
기본 절차는 비슷합니다. 버켓에 들어있는 토큰양이 들어오는 패킷 양만큼 존재한다면 포워딩하고 그렇지 않다면 delay 합니다. delay 된 패킷이 다시 포워딩 되기 위해선 버켓에 토큰이 채워져야 하는데 이 방식이 조금 다릅니다.
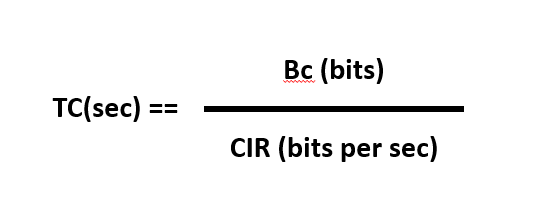
토큰은 위의 식을 기반으로 하는 Time interval(TC)에 의해 주기적으로 추가됩니다. 이 때 의아한 부분이 생길 수 있는데 결국 패킷을 저장했다가 메모리가 감당하지 못해 패킷을 삭제하는 "혼잡"이 발생하는데 어떻게 이런 방식으로 혼잡을 회피할 수 있나요?
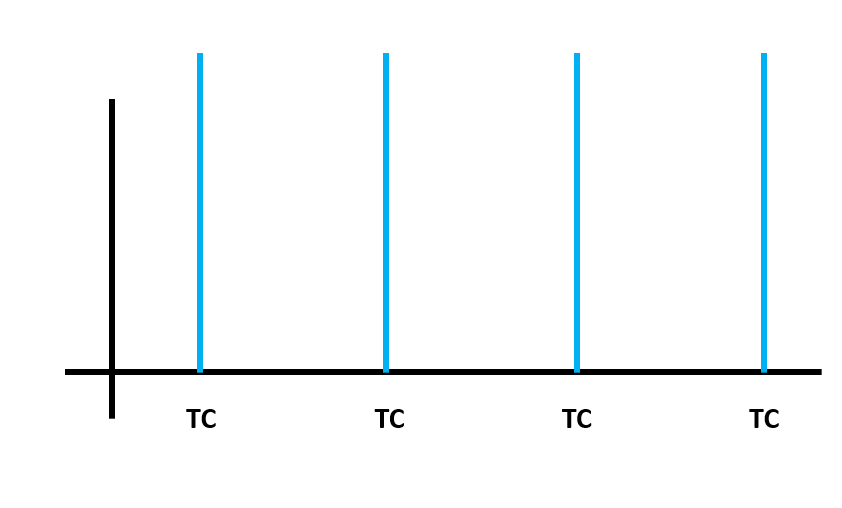
우리는 이를 위해 앞에서 구한 TC간격으로 1초를 나눕니다. 그리고 그 간격마다 bit를 나누어 전송하는 방법을 이용합니다. 따라서 토큰이 존재한다면 바로 포워딩 하지만 버켓에 충분한 양의 토큰이 없다면 다음 TC, 즉 다음 간격까지 기다렸다가 패킷을 포워딩하게 되는 것입니다.
혼잡 회피
폴리싱 과정을 거친 후 버퍼링된 큐가 정해지면 큐에 임시저장되는데 이 때 대기열에 추가되는 패킷에 대한 스케줄링 방법을 혼잡회피라고 합니다. 입력 패킷이 출력 패킷보다 많은 상황에서 패킷을 처리하는 기법입니다. 이에는 3가지의 기법이 있습니다.
Tail drop, WTD, WRED가 그 주인공입니다.
Tail drop 부터 알아보겠습니다. Tail drop은 가장 기본이 되는 방식으로 큐가 메모리가 감당할 수 없는 수준으로 가득차게 되면 이 후 큐로 들어오는 모든 패킷을 삭제하게 됩니다. 이는 결과적으로 통신되어야 할 패킷을 삭제하는 것이므로 좋지 않은 방식입니다. 따라서 대체적으로 WRED를 이용합니다. (WTD는 자료가 많이 없어서 잘 모르겠습니다).
WRED를 이용하기 전에 Tail drop만을 이용하면 발생하게 되는 TCP Global Syncronization에 대해 알 필요가 있습니다. Window Size 다들 아시죠? TCP는 통신을 할 때 Window Size를 딱 맞게 전송하는 것이 아닌 천천히 혼잡이 발생하지 않는 선까지 늘리면서 통신하게 됩니다. 이 때 혼잡이 발생하여 패킷이 삭제되게 되면 Window Size를 줄이고 이를 다시 그 전까지 늘리는 "Slow Start"라는 과정을 거치게 되는데 혼잡이 발생할 때 이 과정이 끊임없이 반복되는 현상이 생깁니다. 그리고 이 현상이 발생했음은 하나의 소스에서 발생하는 현상이 아니라 이 네트워크를 통과하는 모든 소스들의 트래픽에서 발생하게 되기 때문에 이를 TCP Global Syncronization이라고 부르며 혼잡이 발생할 뿐 아니라 대역폭의 자원을 효율적으로 이용할 수 없게 됩니다. 이를 해결하기 위해 WRED라는 기술이 존재합니다.
WRED의 기본 절차는 Tail drop이 발생하기 까지 기다리는 것이 아닌 큐의 길이를 모니터링하게 됩니다. 3가지의 지표를 가지고 큐의 길이를 모니터링 하게 되는데 Minimum threshold, Maximum threshold, MPD(Mark Probability Denominator) 입니다.
| 용어 | 설명 |
| Minimum threshold | 패킷 드랍이 시작되는 임계값 |
| Maximum threshold | 모든 패킷이 삭제되는 임계값 |
| MPD(Mark Probability Denominator) | 큐의 깊이가 Maximum threshold에 도달 했을 때의 패킷의 총량 |
Minimum threshold에 도달했을 때 WRED는 혼잡을 막기 위해 큐에 들어있는 임의의 패킷을 삭제합니다. Maximum 임계값에 큐의 길이가 가까워질 수록 더 많은 양의 패킷을 삭제하다가 Maximum에 도달하면 모든 패킷을 삭제합니다. 이렇게만 보면 tail drop이랑 크게 다를 것도 없고 임의의 패킷을 삭제한다는 점에서 더 안좋아 보일 수 있습니다. 하지만 주목해야할 점은 Weighted 라는 것입니다. 트래픽의 종류별로 Class를 따로 지정하여 임 임계값들을 다르게 설정할 수 있습니다. 이를 WRED는 traffic profile이라고 하는데 이를 통해 중요한 트래픽은 그 패킷이 삭제되는 한계점을 더 높이 두어 삭제되지 않게 할 수 있습니다.
하지만 주의할 점은 WRED는 TCP에게 Window Size를 알려주는 절차기 때문에 TCP 트래픽에만 유용하며 실제로 패킷을 계속해서 삭제하기 때문에 UDP와 같은 실시간성이 중요한 데이터에는 오히려 독일 수 있습니다. 그리고 하나의 특징으로 네트워크에서 가장 많이 트래픽이 발생하는 소스의 트래픽을 활률적으로 더 많이 삭제하기 때문에 혼잡이 발생하면 이런 소스에 존재하는 호스트들은 네트워크가 느려짐을 크게 느낄 수 있습니다.
큐잉과 스케쥴링
마지막으로 큐잉과 스케쥴링입니다. 앞의 일련과정을 거치고 난 후의 패킷들이 우선순위에 의해 따로 따로 큐에 적재되고 그 우선순위에 의해 트래픽들이 외부로 나갈 때의 정책이라고 생각하시면 됩니다. 스케쥴링 보다는 큐잉을 더 깊게 다루겠습니다.
아래는 큐잉 기법에 대한 간단한 설명입니다.
| 종류 | 설명 |
| FIFO | 가장 기본적인 방식의 큐입니다. 혼잡을 발생시키는 큐 |
| WFQ(Weighted Fair Queueing) | 모든 네트워크에 공정한 대역폭을 제공하는 자동 스케줄링 기법으로 분류 옵션을 구성할 수 없음, 패킷에 가중치나 우선순위를 부여하여 후름 별로 분류 |
| CBWFQ(Class based Weighted Fair Queueing) | WFQ의 확장으로 사용자 정의 트래픽 분류를 지원함 |
| LLQ(Low Latency Queueing) | CBWFQ + Priority Queuing 버전임 |
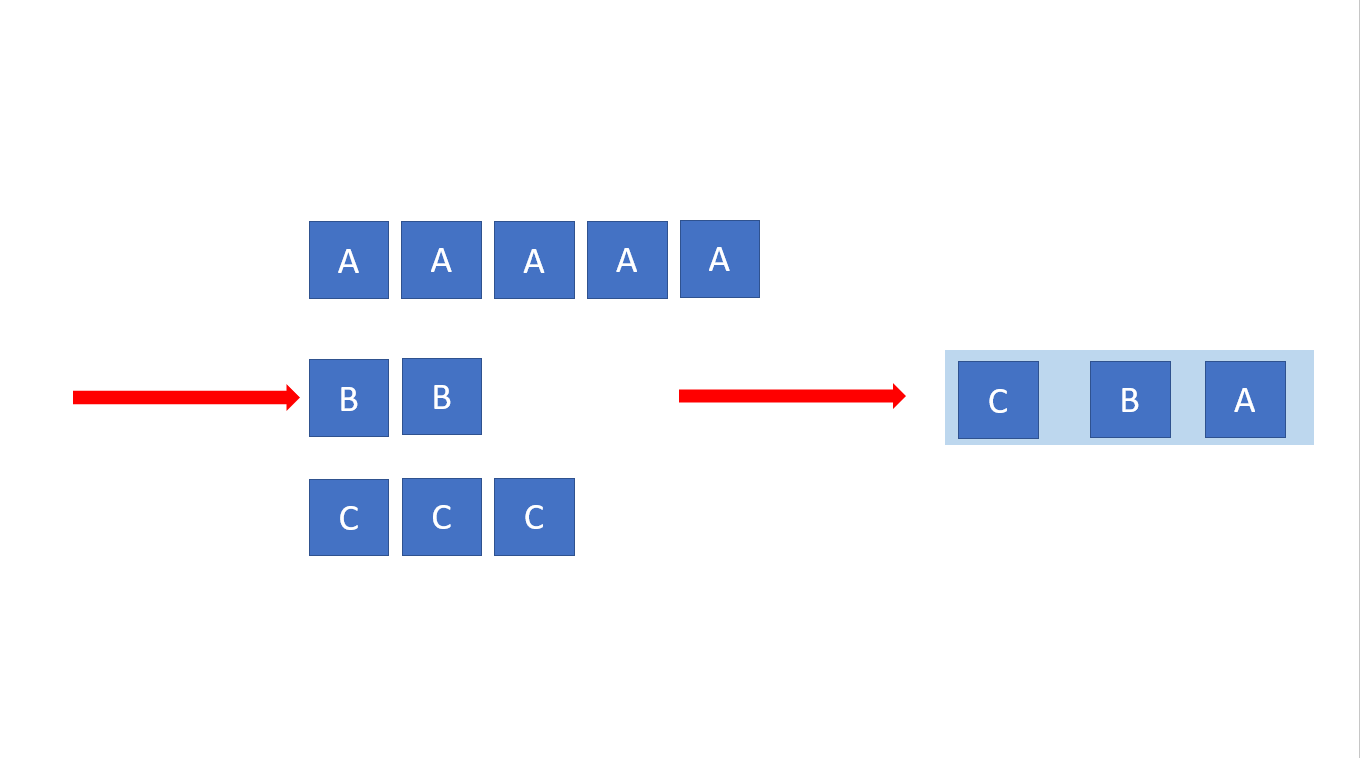
WFQ 방식에 대해 간단하게 설명하는 그림입니다.
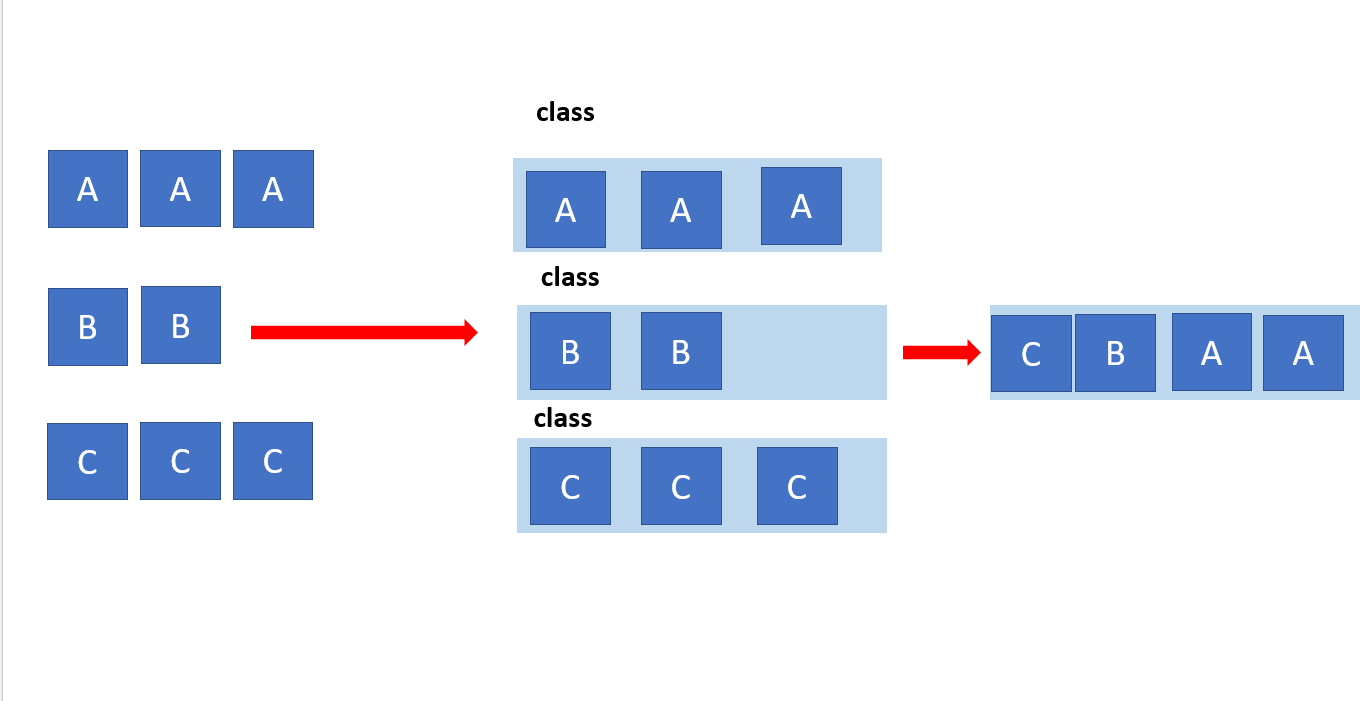
CBWFQ에 대해 설명하는 그립입니다.
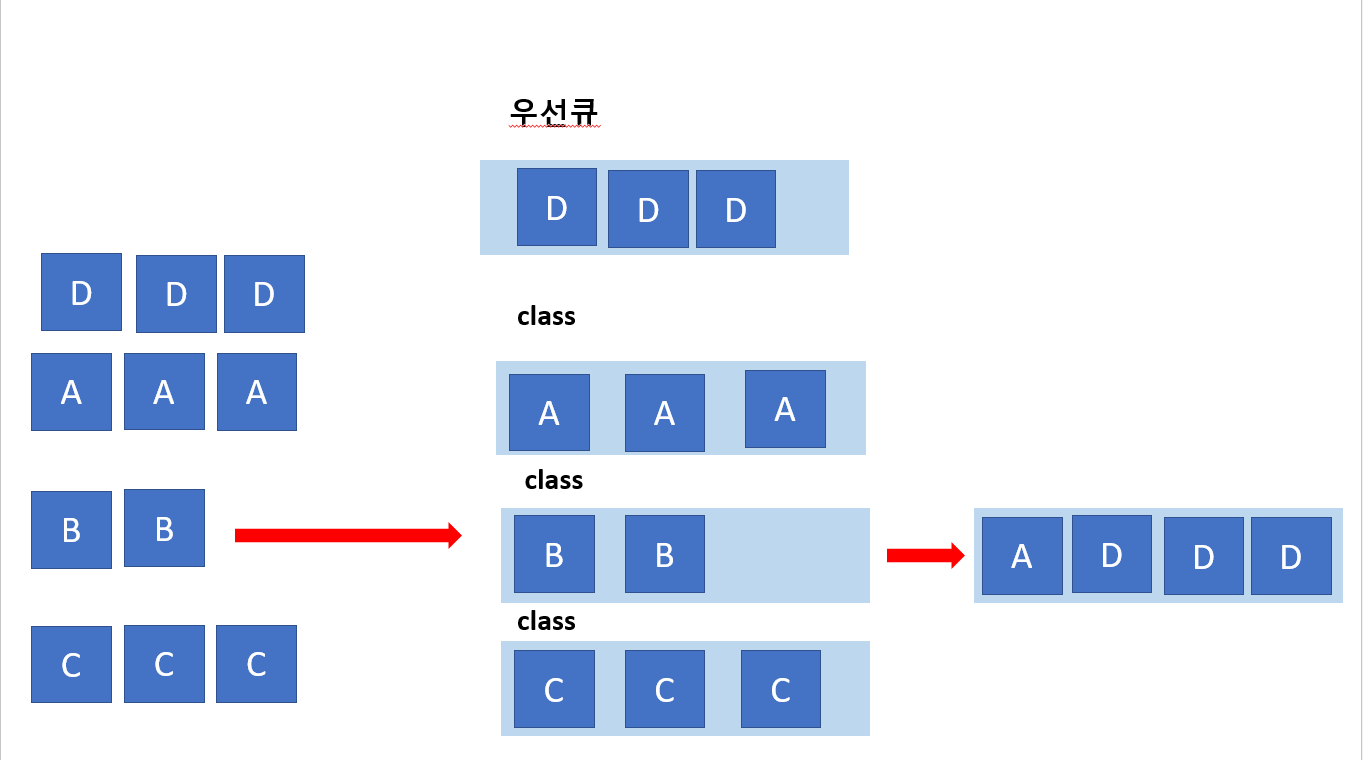
LLQ에 대해 설명하는 그림입니다.
아래는 스케쥴링 기법에 대한 간단한 설명입니다.
| 종류 | 설명 |
| WRR | Weighted Round Robbin : 그냥 라운드 로빈 정해진 비율대로 돌아가며 스케쥴링 |
| DWRR | Deificit Weighted Round Robbin : WRR이랑 비슷한데 dificit counter라는 것을 두어서 전송 순서가 되도 이 값보다 큐의 값이 작으면 전송 X 하고 큐의 카운터 값을 올림 |
| 최우선 큐잉 | 기법이라기 보단 최우선 큐를 두고 이에 적재되는 트래픽은 어떤 트래픽보다 먼저 포워딩 됨 (대부분 음성 데이터나 영상 데이터) |
| SRR | Shaped round robbin |
'네트워크 > 네트워크 일반' 카테고리의 다른 글
| OPNsense로 DHCP 설정하기 (0) | 2023.10.03 |
|---|---|
| OPNsense로 Static NAT, Source NAT, 포트포워딩 하기 (0) | 2023.10.03 |
| CBAC 실습 및 URL FILTER (0) | 2023.06.19 |
| Reflexive ACL(가난한 자의 stateful inspection) (0) | 2023.06.18 |
| VLAN hopping(DTP,Native VLAN, Switch spoofing, Double tagging attack) (0) | 2023.06.02 |