
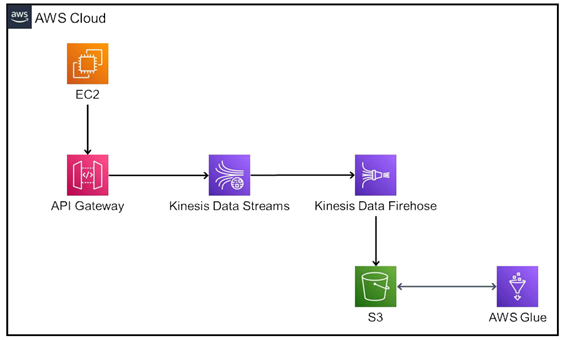
위 토폴로지를 통해 진행해보도록 하겠습니다.
들어가기 전 간단한 이론
Kinesis
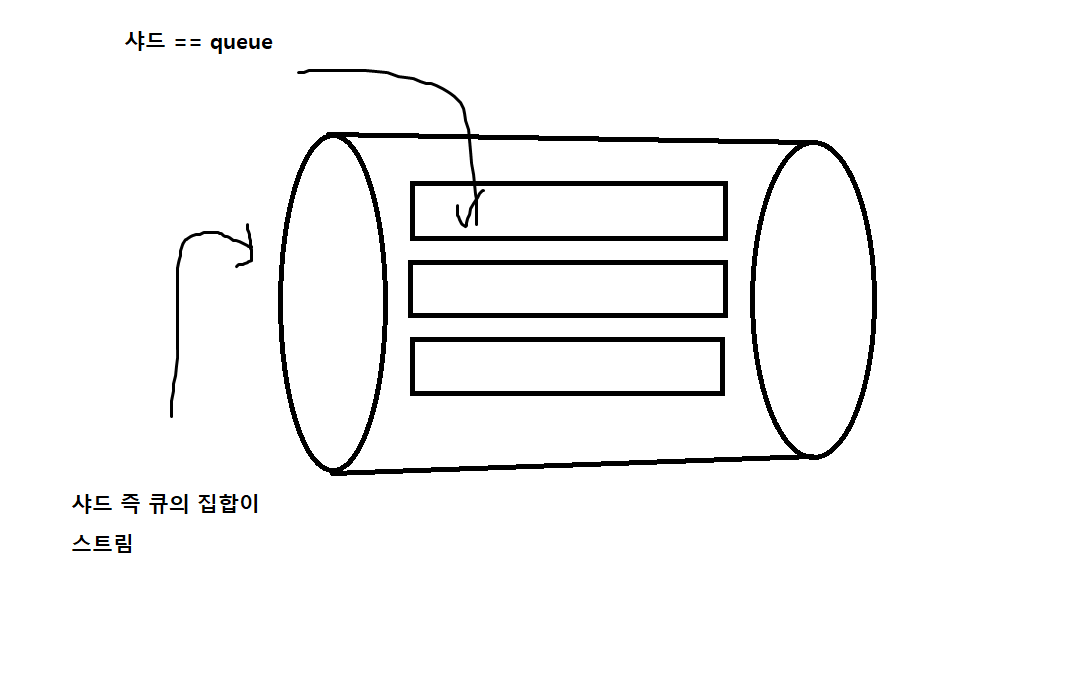
아래에는 길게 길게 적어놨는데 사진만 이해하시면 됩니다. 따라서 실시간 데이터를 샤드 즉 큐에 저장했다가 분석 툴인 kinesis analysitc에 보내 분석하거나 S3에 저장해서 Glue를 통해 분석하는 행위를 할 수 있습니다.
| 용어 | 내용 |
| 데이터 레코드 | 데이터 레코드는 Kinesis에 저장되는 데이터의 단위이다. 데이터 레코드는 변경되지 않는 일련 번호, 파티션 키, data blob으로 구성된다. |
| 용량 모드 | 용량이 관리되는 방식과 데이터 스트림 사용 요금이 부과되는 방식을 결정한다. |
| 보유 기간 | 데이터 레코드가 스트림에 추가된 후 액세스할 수 있는 기간으로 기본값은 생성 후 24시간이다. (24시간 이상일 경우 추가 요금이 청구된다) |
| 생산자 | 생산자는 레코드를 kinesis data stream에 넣는 주체, ex) 로그 데이터를 스트림으로 보내는 웹 서버 |
| 소비자 | 레코드를 가져와 처리하는 주체 : Amazon kinesis Data Streams 애플리케이션 |
| Amazon kinesis Data Streams 애플리케이션 | 일반적으로 EC 인스턴스 플릿에서 실행되는 스트림의 소비자. |
| 샤드 | 스트림에서 고유하게 식별되는 데이터 레코드 시퀀스. 각 샤드는 읽기의 경우 초당 최대 5개의 트랜잭션, 데이터 읽기 속도 2MB, 쓰기의 경우 초당 최대 1000개의 레코드, 초당 최대 총 데이터 쓰기 속도 1MB를 지원함 |
| 파티션 키 | 스트림 내에서 샤드별로 데이터를 그룹화하는데 사용된다. 데이터 레코드를 여러 샤드로 분리하여 파티션 키를 통해 데이터 레코드가 속할 샤드를 결정한다. |
| 시퀀스 번호 | 파티션 키마다 고유하게 가진 시퀀스 번호. 영상에서 소개됐던 데이터를 지우지 않고 큐의 위치를 옮긴 다는 내용이 이 시퀀스 번호 내용인듯 |
| 클라이언트 라이브러리(KCL) | 스트림에서 데이터의 내결함성 소비를 지원하기 위해 애플리케이션으로 컴파일 된다. 데이터 읽기를 단순화하고 DB 테이블을 사용하여 제어 데이터를 저장한다. |
| 애플리케이션 이름 | 애플리케이션을 식별한다. 각 애플리케이션에는 애플리케이션에서 사용하는 AWS 계정 및 리전으로 범위가 지정된 고유한 이름이 있어야 한다. 이 이름은 제어 테이블 이름과 CloudWatch의 네임스페이스로 사용된다. |
온디맨드 VS 프로비저닝
- 온디맨드 모드는 Kinesis가 자동으로 샤드를 관리하여 필요한 처리량을 제공한다. 사용한 실제 처리량에 대해서만 비용이 청구되며 워크로드의 증감에 자동으로 수용한다.
- 프로비저닝 모드에서는 데이터 스트림의 샤드 수를 직접 지정해야 한다. 데이터 스트림의 총 용량은 샤드 용량의 합으로 샤드를 늘리거나 줄일 수 있으며 샤드 수에 대한 시간당 요금이 청구되니다.
API gateway
API 요청을 받아들이고 처리할 수 있는 게이트웨이입니다. 사실 API gateway를 이해하려기 보다는 REST API에 대한 이해를 하고 나서 보시는게 더 이해가 잘됩니다. 쉽게 얘기하자면 들어오는 API 요청에 따라서 요청에 대한 반환을 손쉽게 다룰 수 있도록 해주는 리소스입니다.
Glue
ETL(추출 변환 적재)를 수행하는 리소스로 원시 데이터를 저정하는 데이터 레이크나 크롤링을 통하여 데이터 합성 변환 등등의 말 그대로 ETL을 수행할 수 있는 리소스입니다. Glue workflow를 통하여 필요한 ETL 과정을 자동화할 수도 있습니다.
IAM 구성
총 2개의 역할이 필요합니다. API gateway의 요청이 kinesis에 접근하기 위한 역할과 Glue가 S3에 접근해 파일을 읽고 변환하여 다시 저장하기 위한 역할입니다.
API용
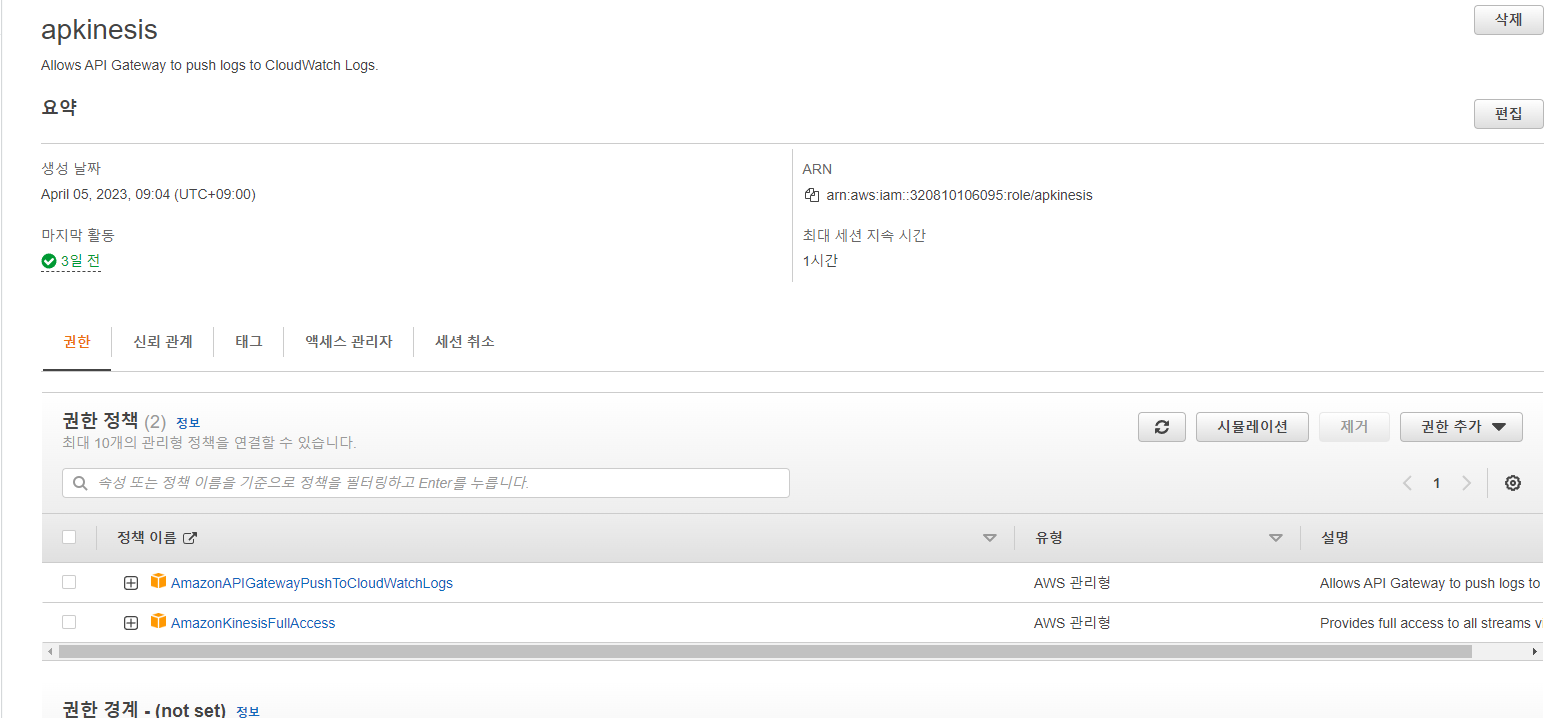
역할 대상을 API gateway로 선택하고 kinesisfullaccess를 부여합니다.
Glue용
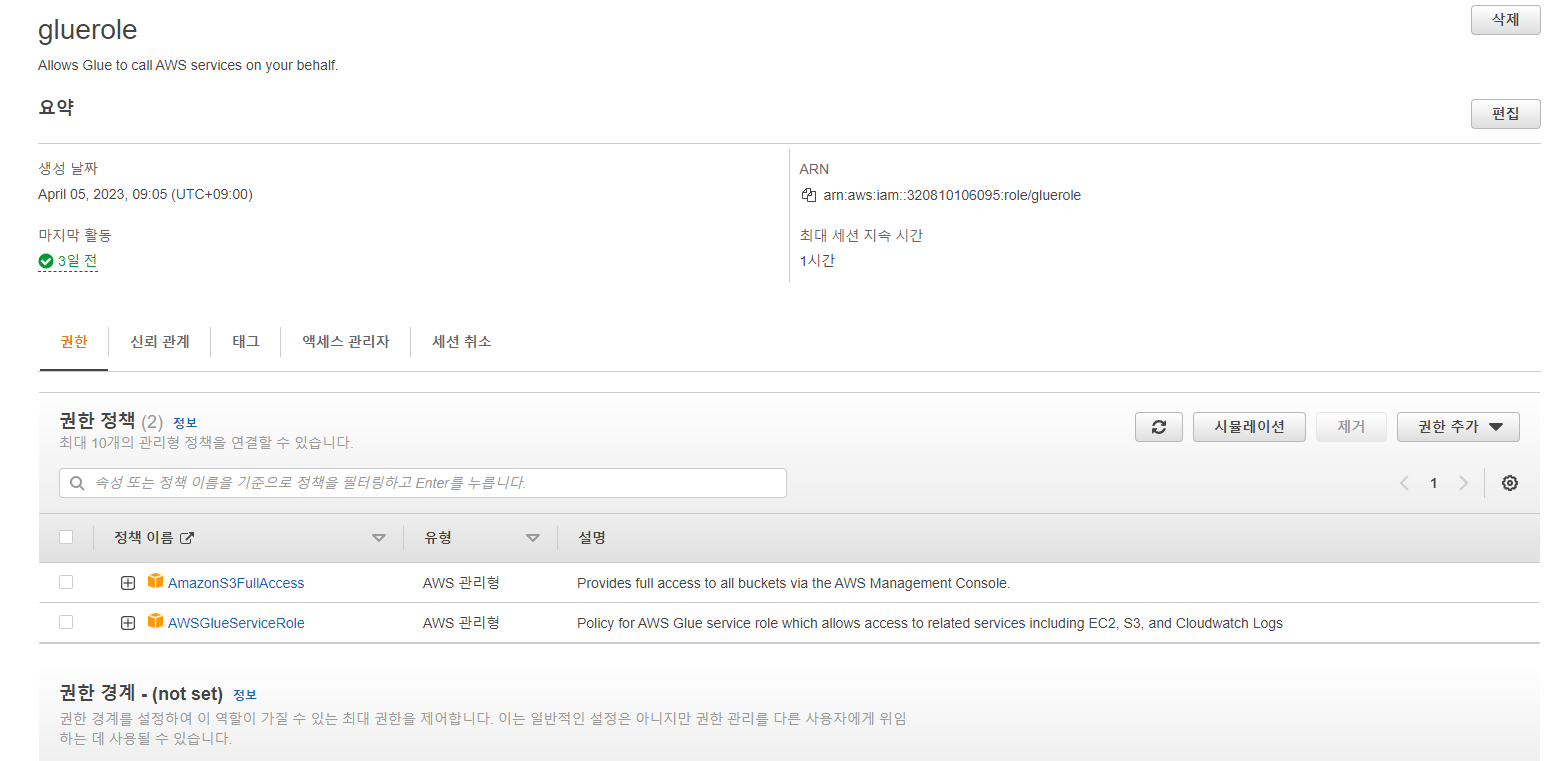
Glue를 돌리기 위한 Glueservicerole과 S3접근을 위한 S3fullaccess 권한을 부여합니다.
API gateway, kinesis 구성
Kinesis 구성
kinesis -> 데이터 스트림
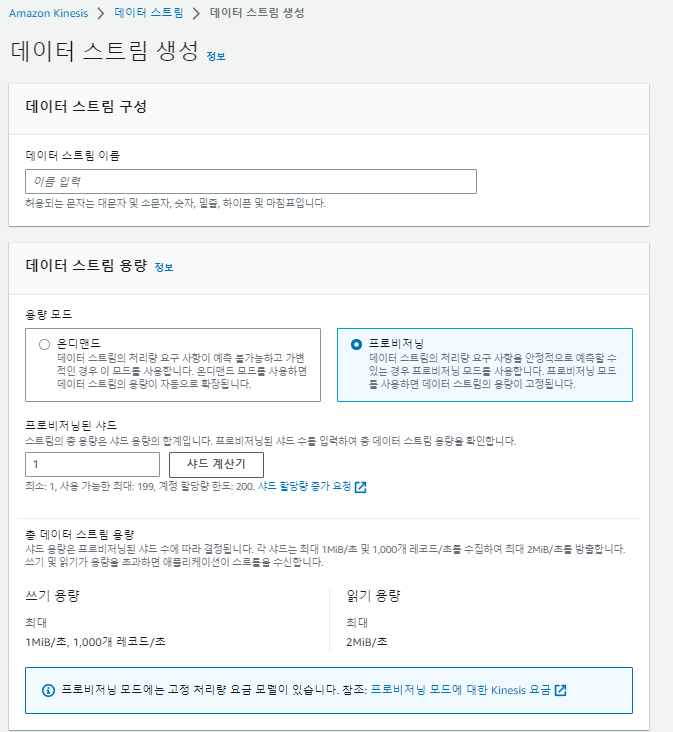
기호에 맞게 설정합니다.
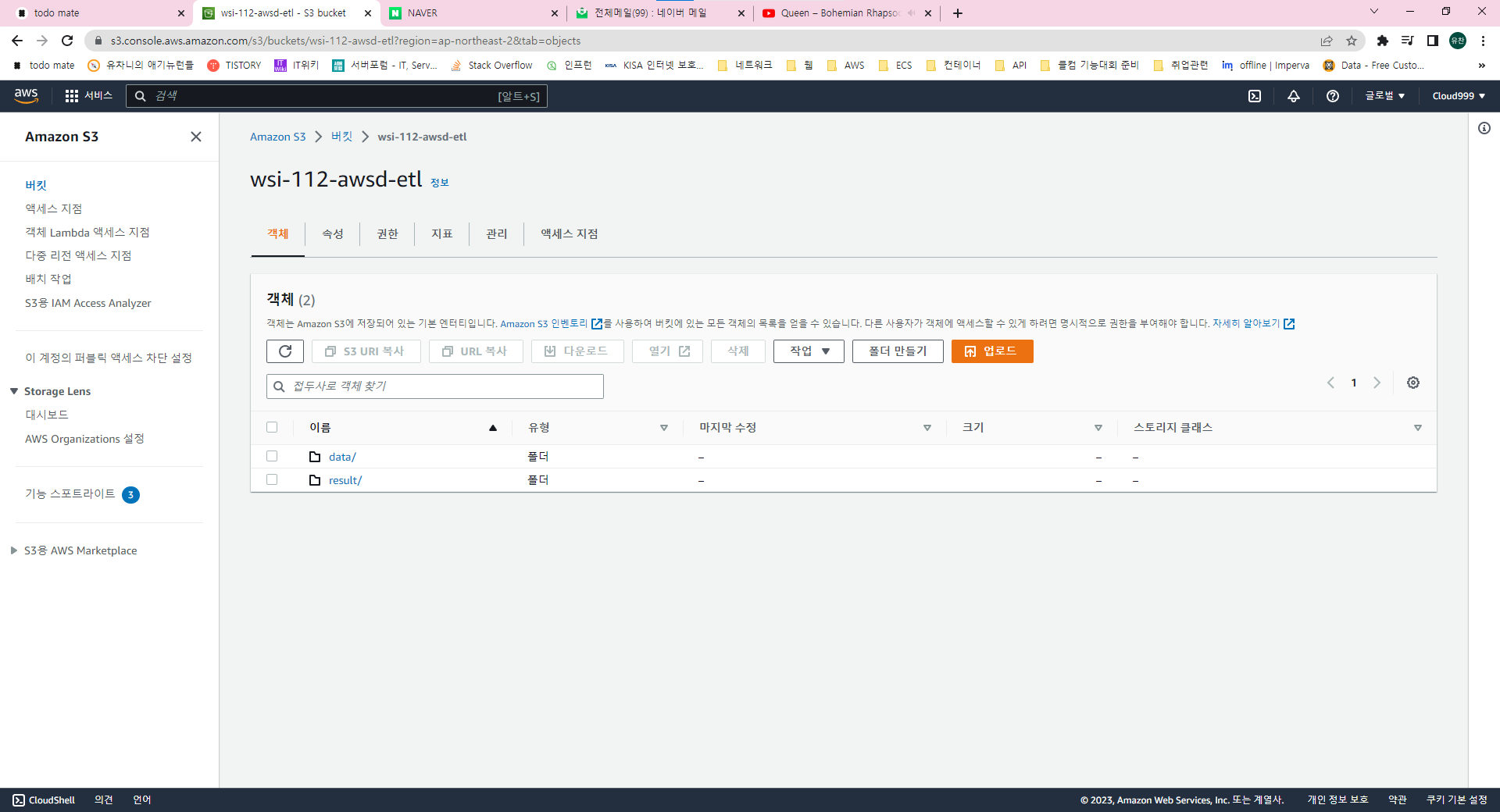
잠시 다시 S3로 이동하여 버킷을 생성합니다. 저는 data 폴더에 데이터를 저장하고 result 파일에 변환한 데이터가 다시 저장되도록 구성해보겠습니다.
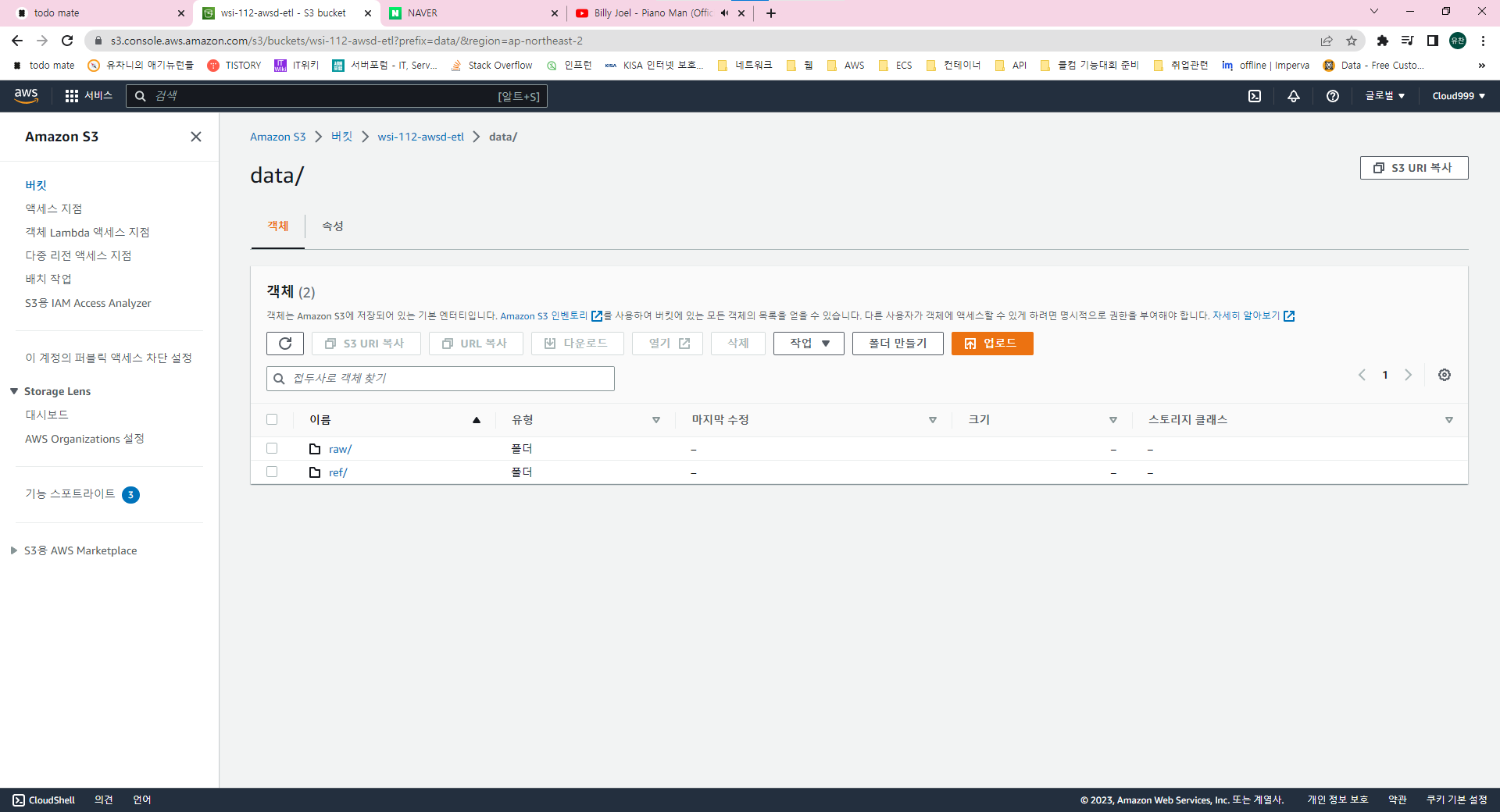
data/raw 폴더와 /ref폴더에 합성할 데이터를 미리 올려두었습니다. 또 API gateway를 통해 등록되는 로그 데이터는 raw 폴더 아래에 저장되도록 해보겠습니다.
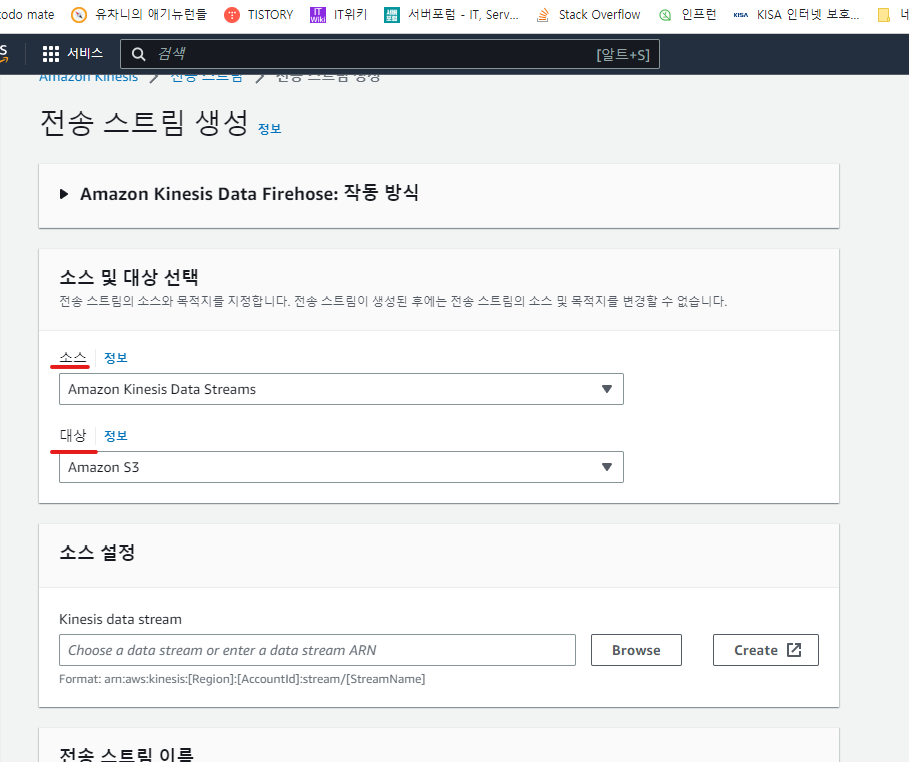
다시 kinesis로 돌아와서 데이터 전송 스트림(firehose)을 생성합니다. 소스를 앞에서 생성한 kinesis 데이터 스트림, 대상을 방금 생성한 s3 버킷으로 지정합니다.
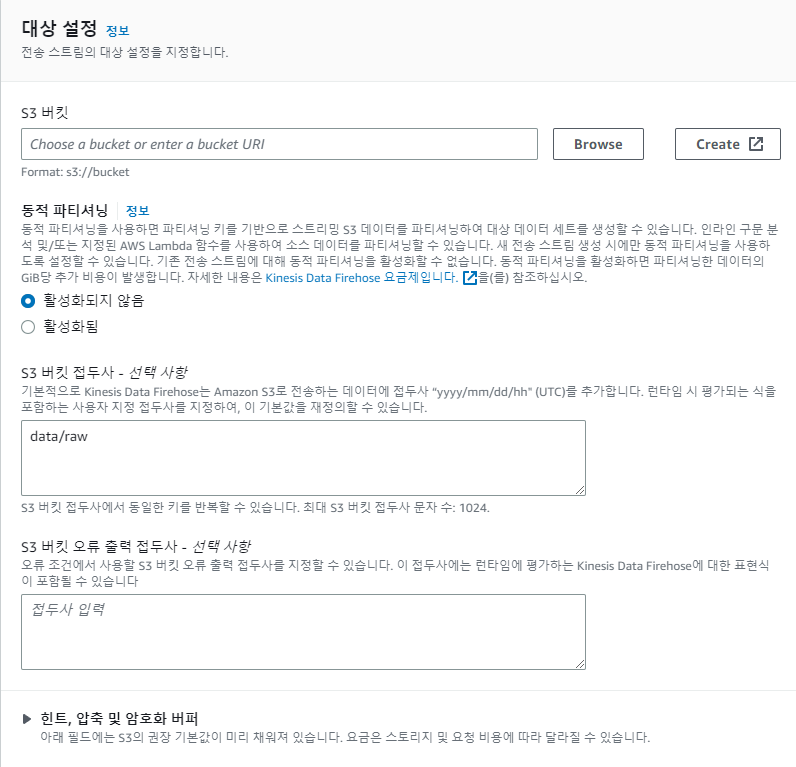
원하는 S3폴더 아래에 데이터를 저장하기 위해선 S3 버킷 접두사를 수정해야합니다. 저는 raw 폴더 아래에 기본 포맷으로 저장하기 위해서 data/raw 라고 적어주겠습니다.
API 구성
API gateway -> API 구성 -> REST API

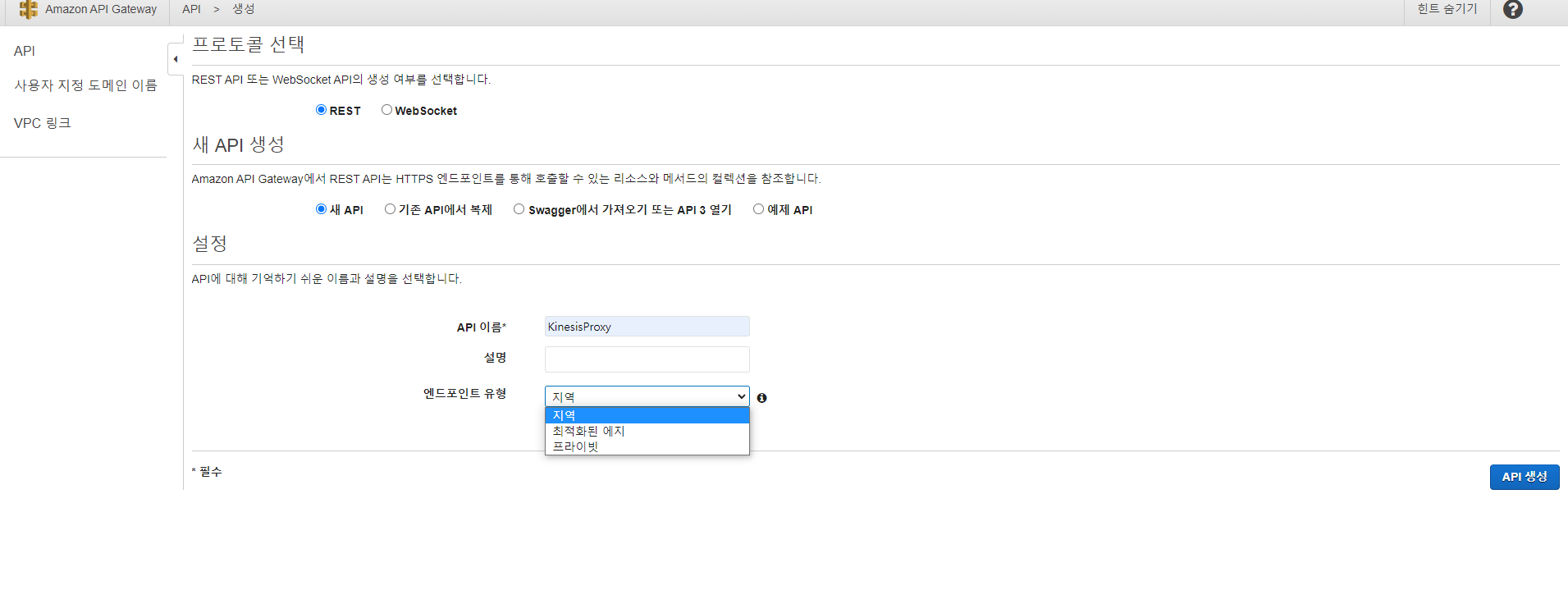
새 API 구성을 선택하고 이름은 상황에 맞게 지어주시면됩니다. API 유형엔 3가지 유형이 있는데 지역, 프라이빗, 최적화 엣지 이렇게 나뉩니다. 지역은 API 배포시 어디에서든 접근할 수 있는 유형이고 프라이빗은 VPC에서밖에 접근하지 못합니다. 또한 리소스 권한 설정을 해줘야해서 번거로우니 지역으로 만들어보겠습니다.
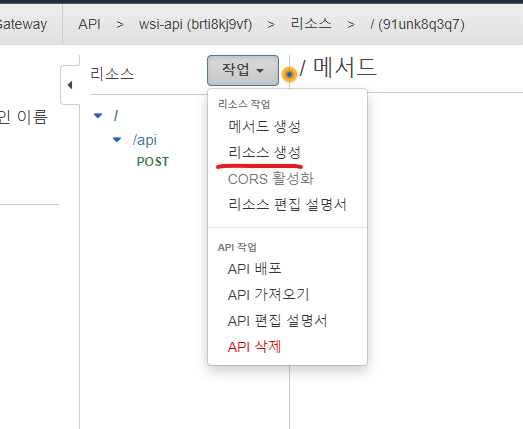
리소스 생성을 해줍니다.
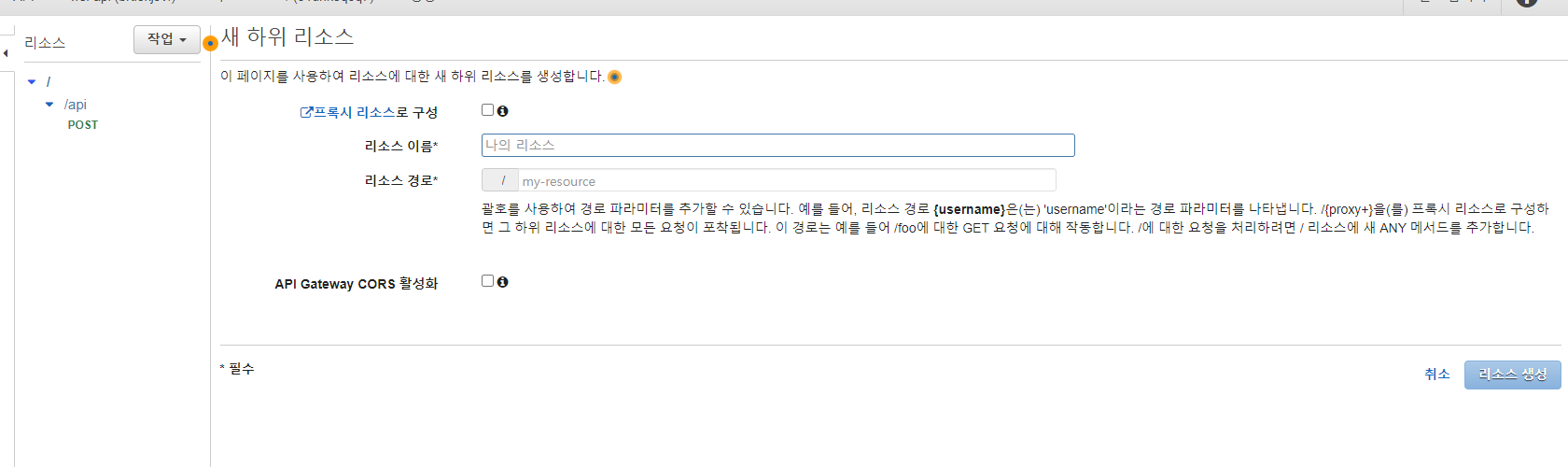
리소스에 원하는 이름을 적어주시면 됩니다. 저는 데이터 스트림을 정적으로 지정해줬기 때문에 하나의 리소스를 만들지 않았지만 정적으로 정해주지 않고 여러개의 데이터 스트림 입력을 받으려면

이런식으로 변수화 해서 선언해주시면 됩니다.
메소드 생성을 해줍니다. 간단하게 POST로 해보겠습니다.
통합요청으로 이동합니다.
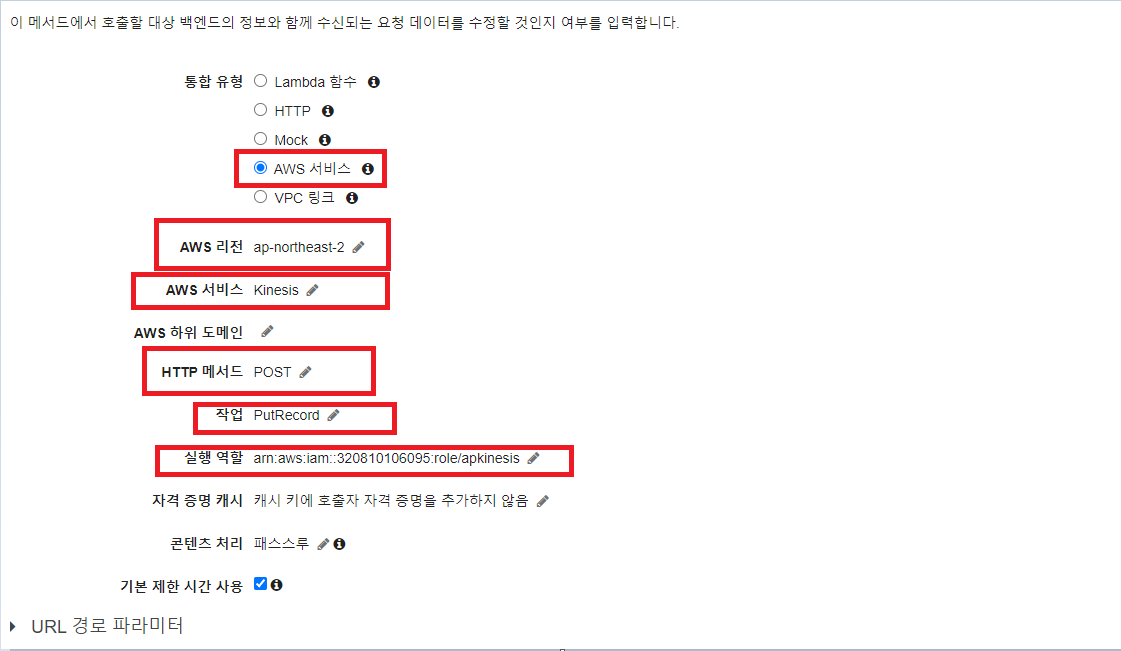
박스 모두 중요한데 위부터 kinesis에게 요청을 보낼거기 때문에 aws 서비스를 선택합니다. 리전은 현재 작업하시는 리전을 선택하시면 됩니다. 서비스는 kinesis를 선택합니다. http 매서드는 kinesis의 모든 api가 post방식으로 구성돼있기 때문에 post방식을 지정해주어야 합니다. ListStream 등등 많은 action이 있지만 저는 데이터를 저장하기 위해 PutRecord로 생성했습니다. 실행역할에는 처음에 생성해줬던 IAM역할의 arn을 복사해서 입력해주어야 합니다.

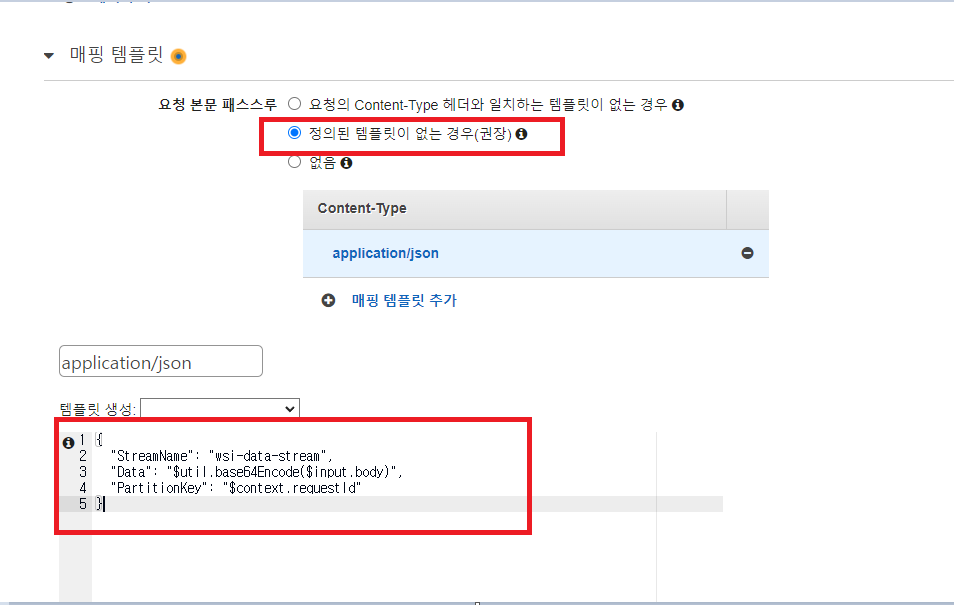
HTTP 헤더와 매핑 템플릿을 다음과 같이 구성해줍니다. 템플릿 생성에서는 다양한 내용들이 있는데 저는 바디 형식의 데이터를 바로 받아들일 수 있도록 했습니다. StreamName에 데이터 스트림의 이름을 적어줍니다. 만약 변수명으로 여러개의 데이터 스트림을 작동시키고 싶으시다면 stream-name이라고 적어주시면 될겁니다.
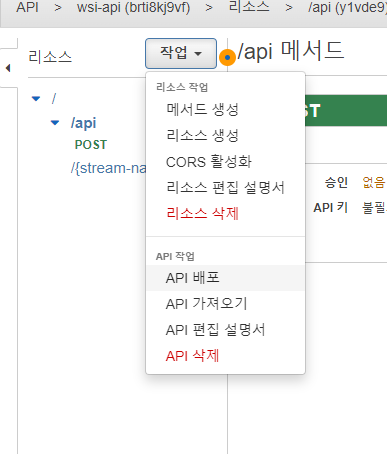
이제 생성한 API를 배포합니다.
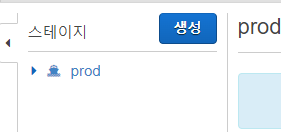
저는 prod라는 이름으로 생성해봤습니다.

curl -X POST -H 'Content-Type:application/json' -d '{"name" : "idiot","gender" : "male"}' <생성된 url>/api위 명령어로 데이터 스트림에 데이터를 전송했습니다.
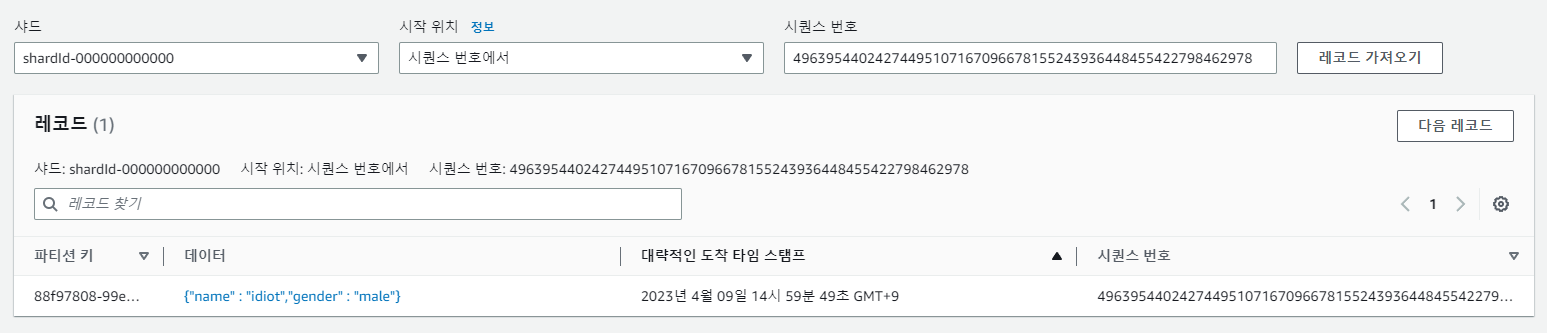
정상적으로 저장된 것을 확인할 수 있습니다.
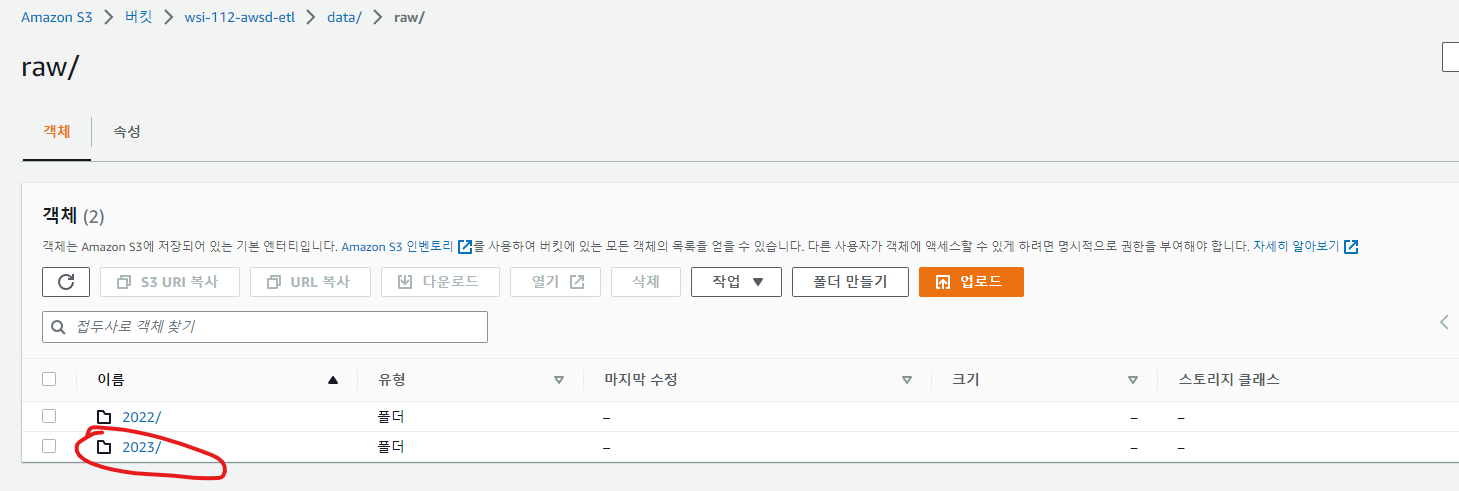
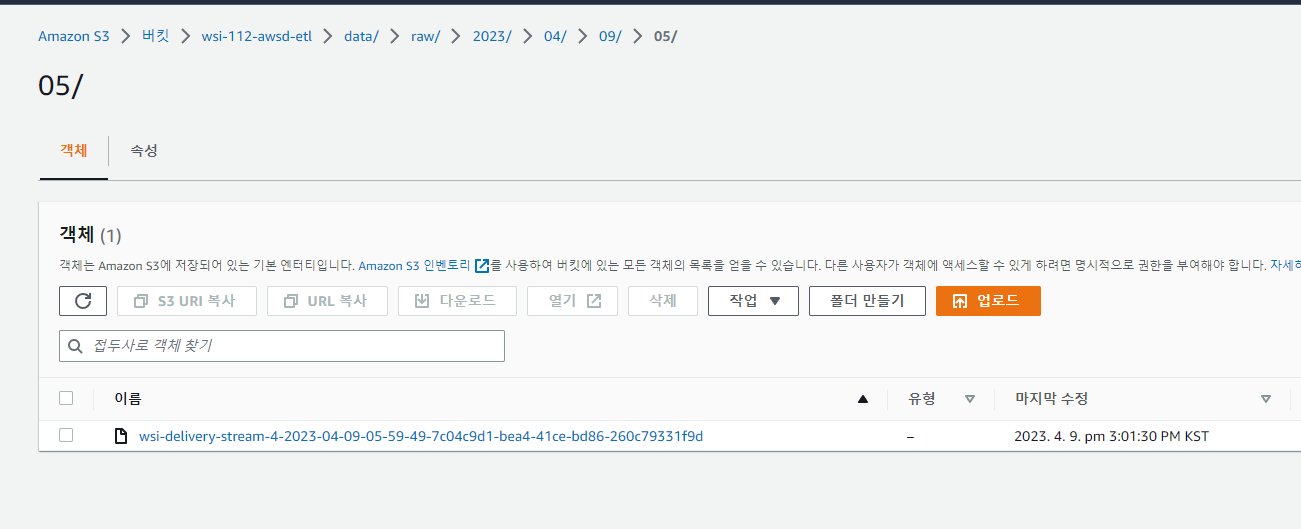
정상적으로 저장된 것을 확인할 수 있습니다.
Glue 구성
Glue catalog로 이동해 데이터베이스를 추가합니다.
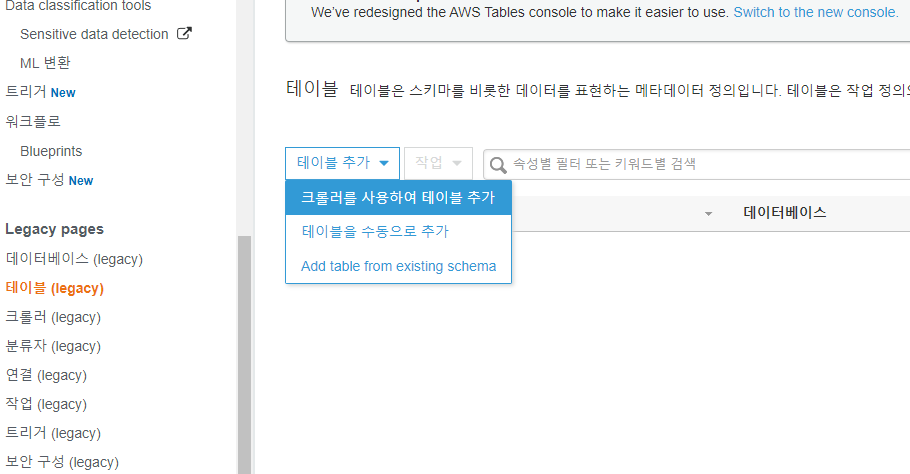
크롤러를 사용하여 테이블 추가를 선택합니다.
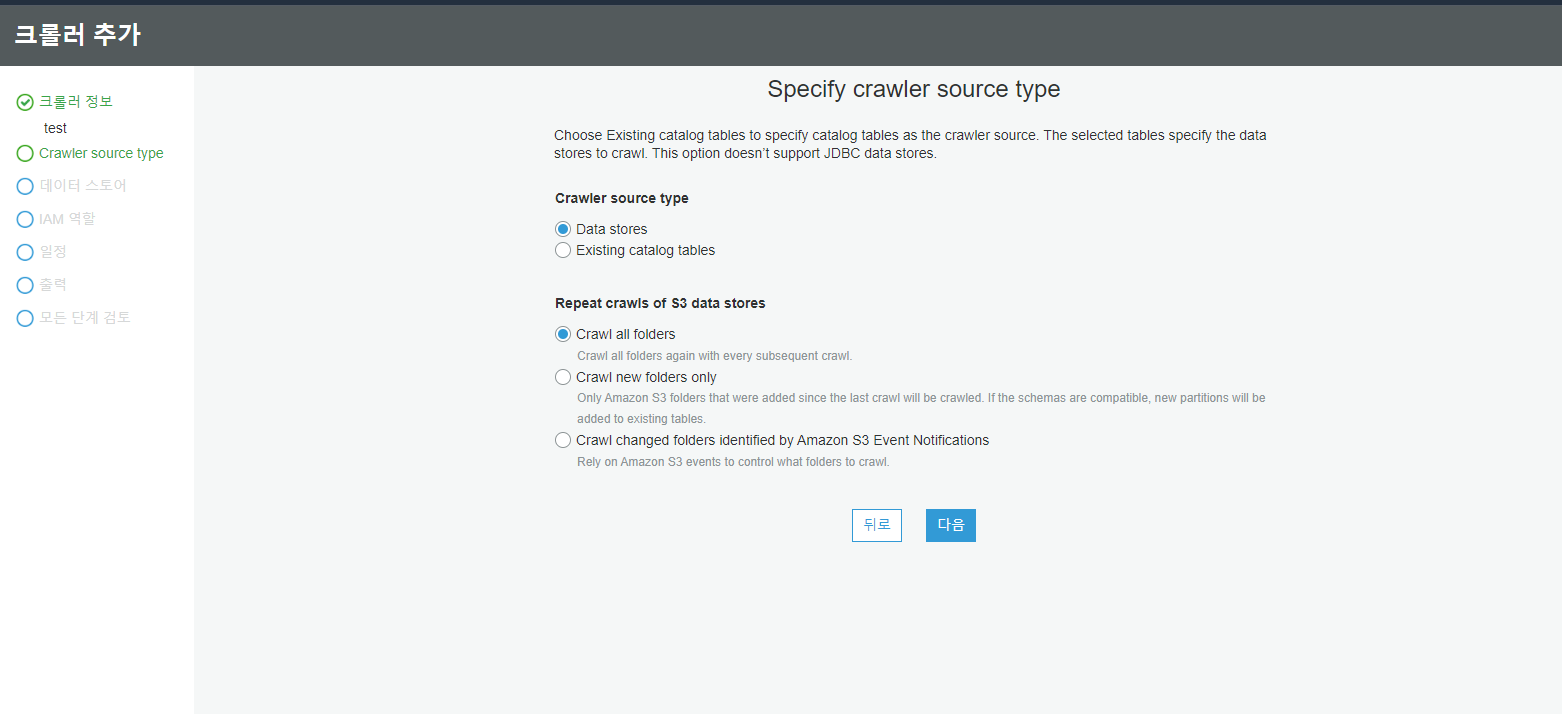
| Crawl all folders | 전체 데이터 집합을 크롤링합니다. |
| Crawl new folders only | 마지막 크롤러 실행 이후에 추가된 폴더만 크롤링합니다. |
| Crawl changed folders identified by Amazon S3 Event Notifications | 새로운 폴더가 생기는 이벤트가 발생할 때 크롤링하게끔 구현이 가능합니다. |
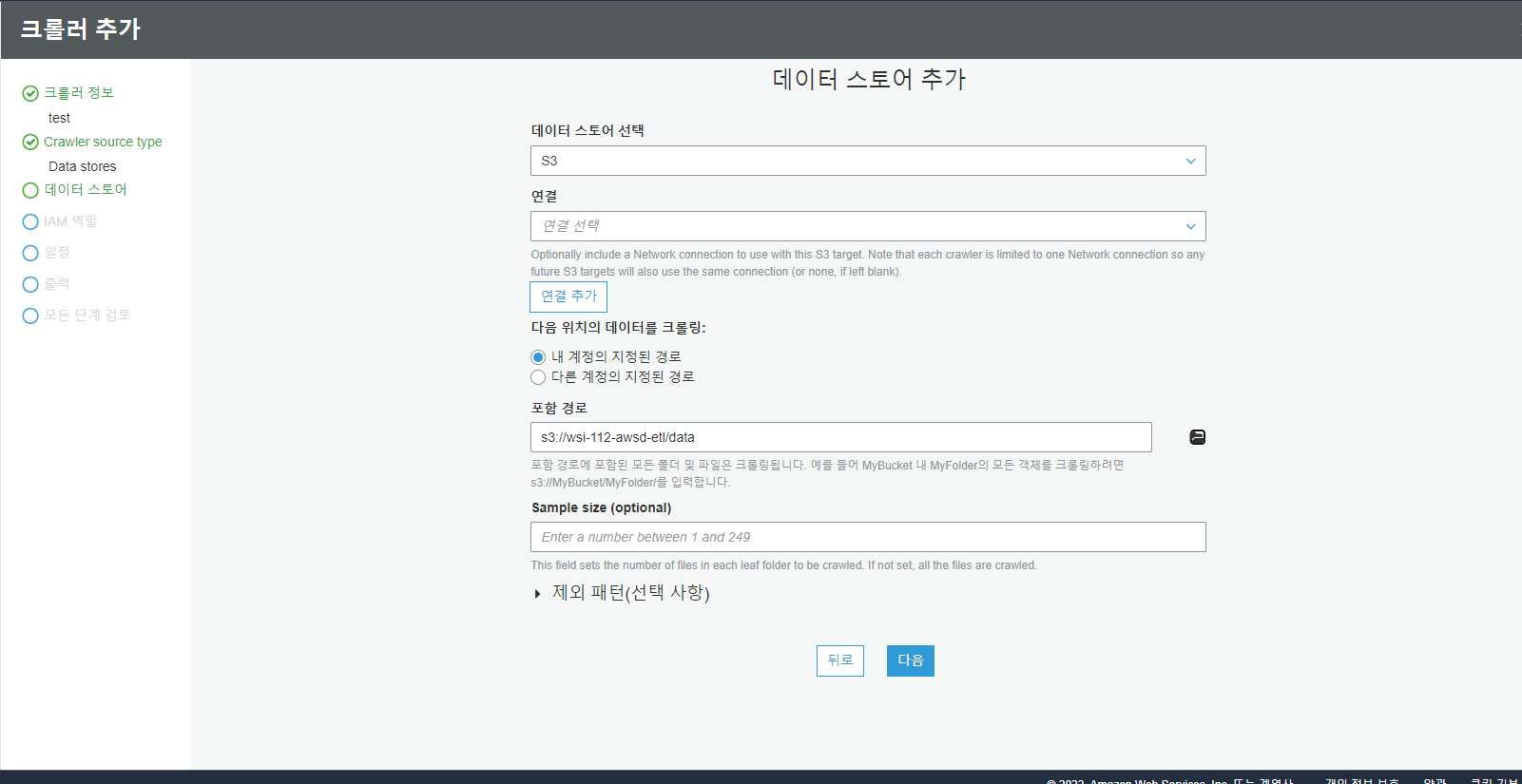
데이터 스토어를 S3로 생성하고 포함 경로를 데이터가 저장되는 곳으로 지정햐줍니다.
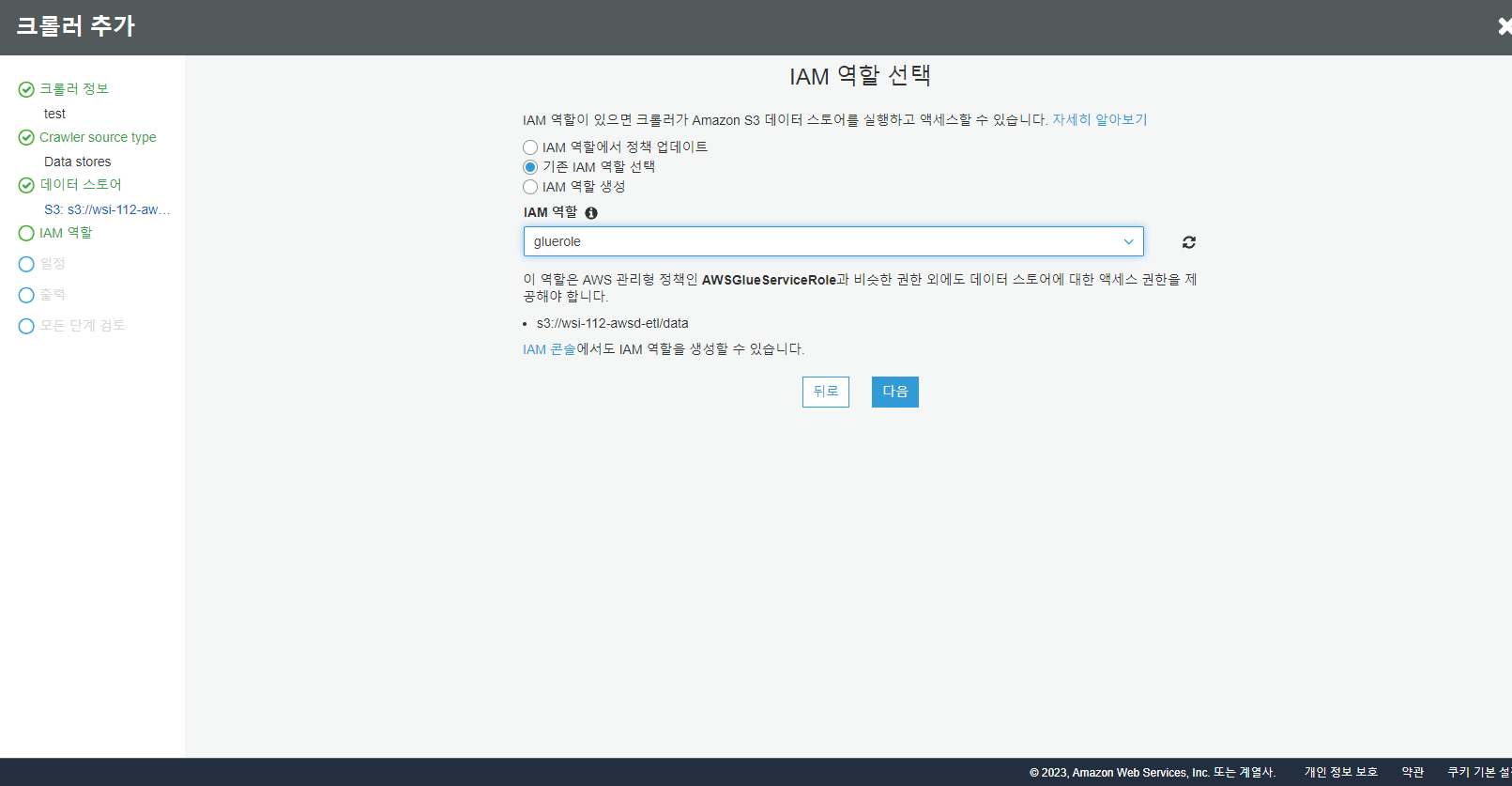
기존에 설정했던 glue 정책을 연결합니다.
제가 실행하고 싶을때 실행되도록 하겠습니다. cron 설정으로 주기적으로 실행되게 만들 수 있습니다.
테이블이 저장될 데이터베이스를 선택합니다.
생성된 크롤러를 선택하고 실행합니다.
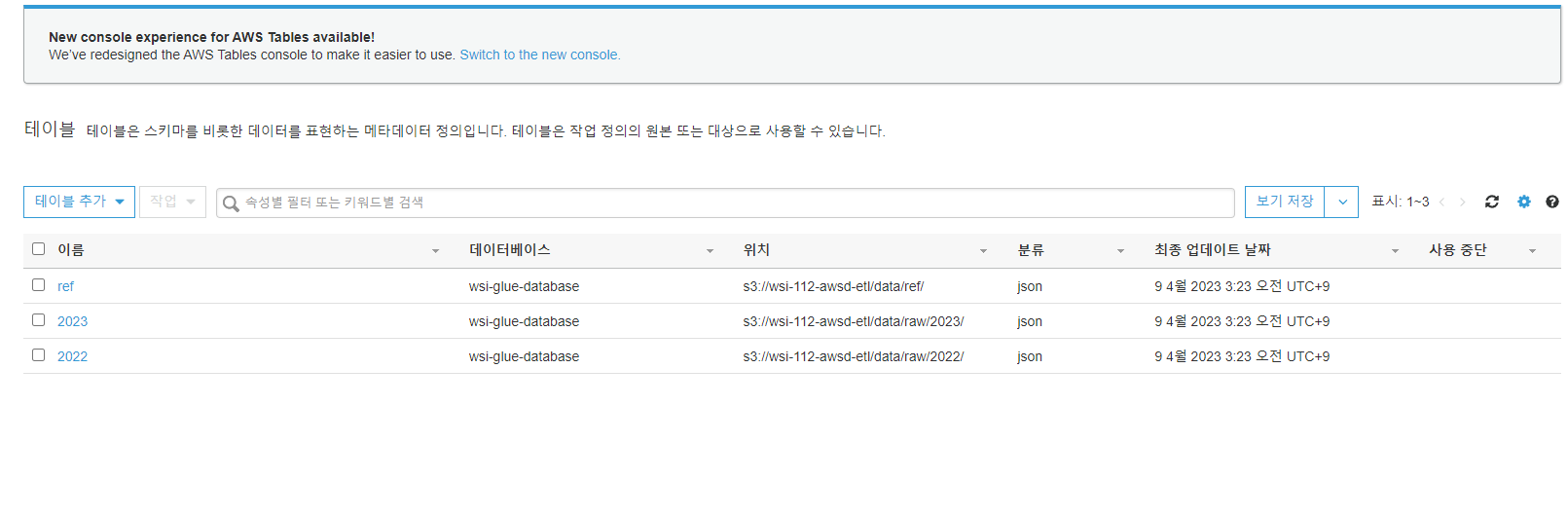
조금 기다리고 나면 테이블이 추가된 것을 확인할 수 있습니다.
이제 ref의 데이터와 2022의 데이터를 비교해서 병합하는 ETL 작업으로 이동합니다.
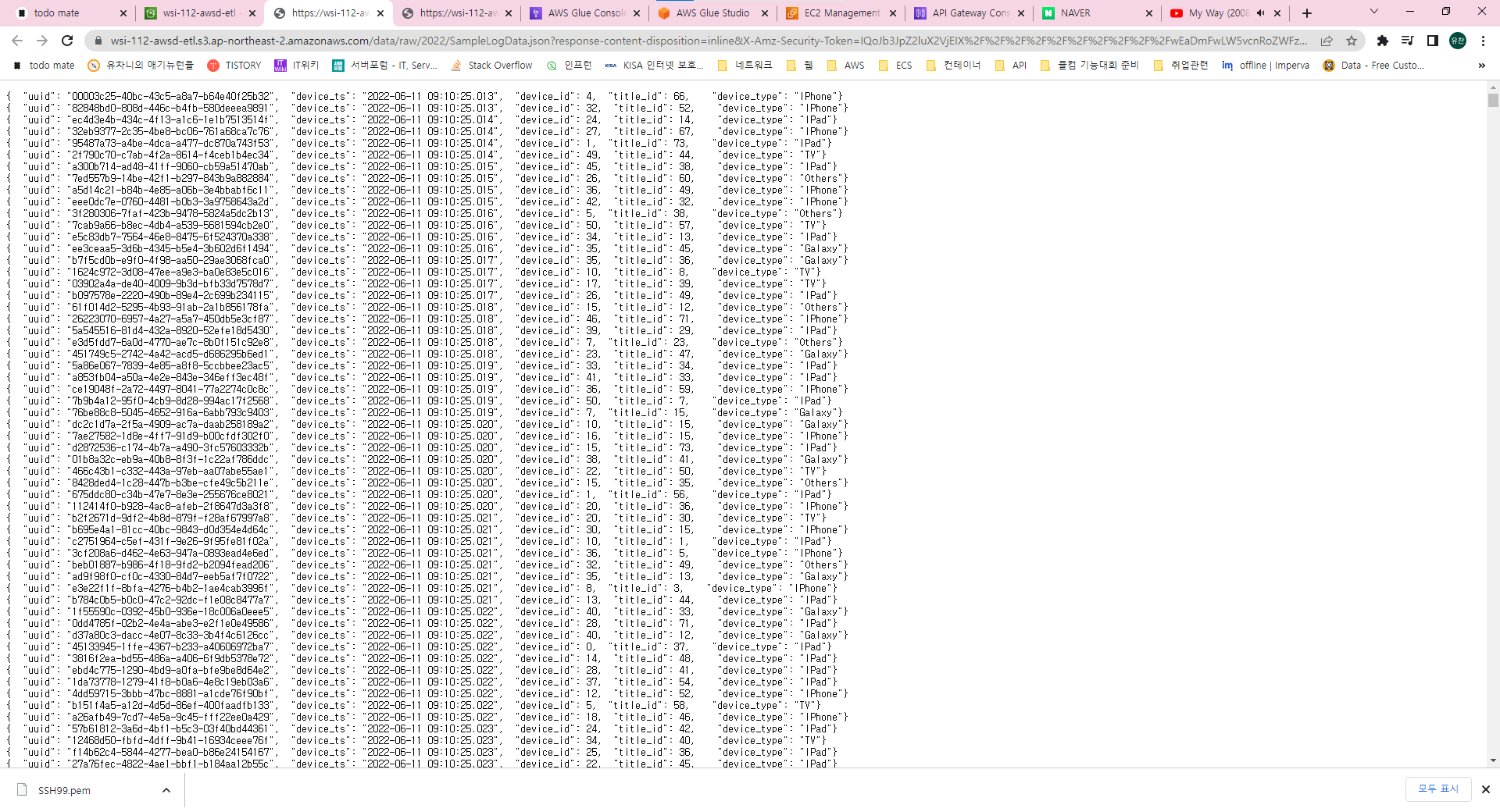
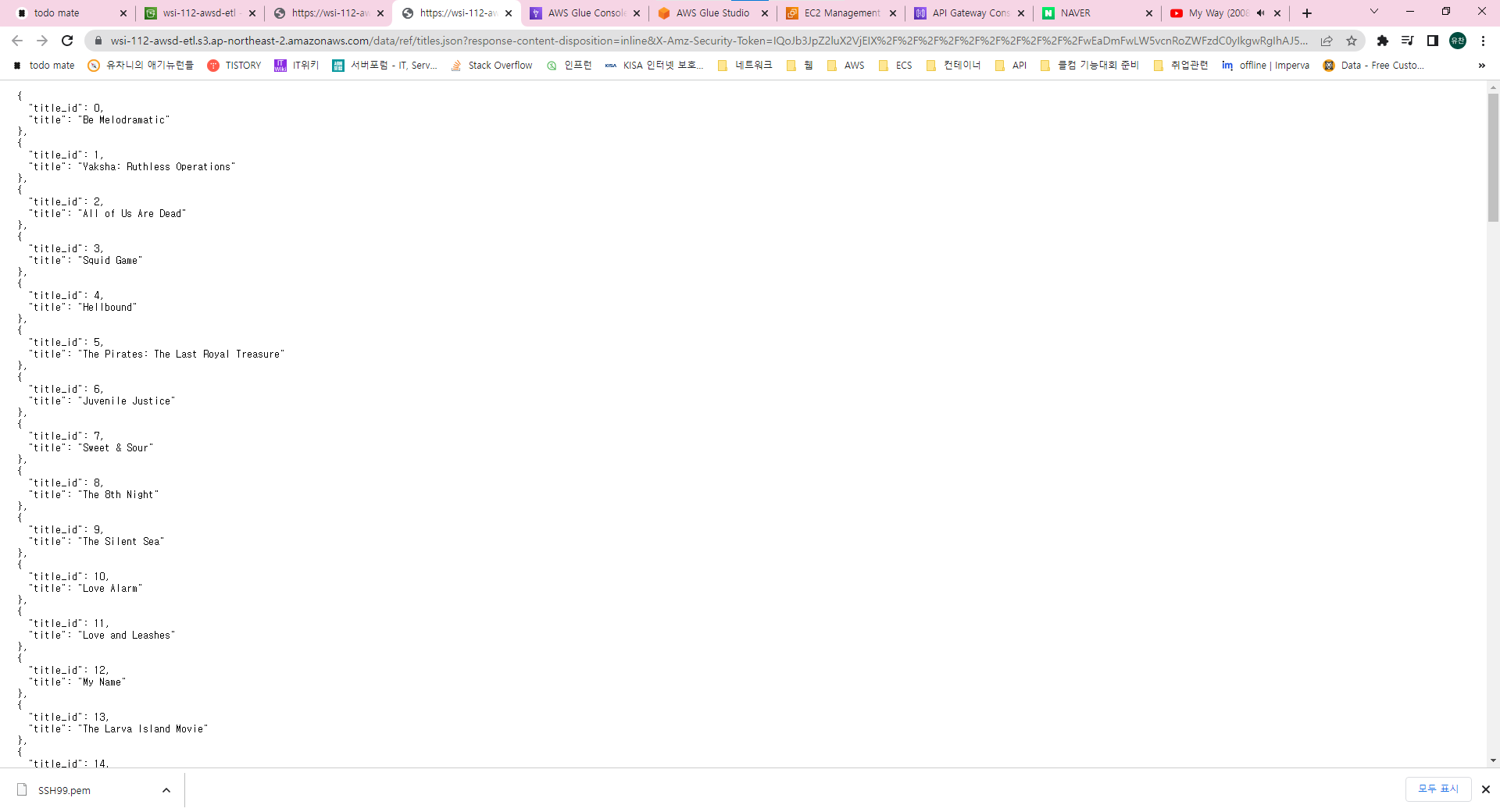
사용할 데이터들은 이렇게 구성되어 있습니다.
title_id가 같으면 titled_id의 title을 원본 데이터에 삽입하도록 구성할 것입니다.
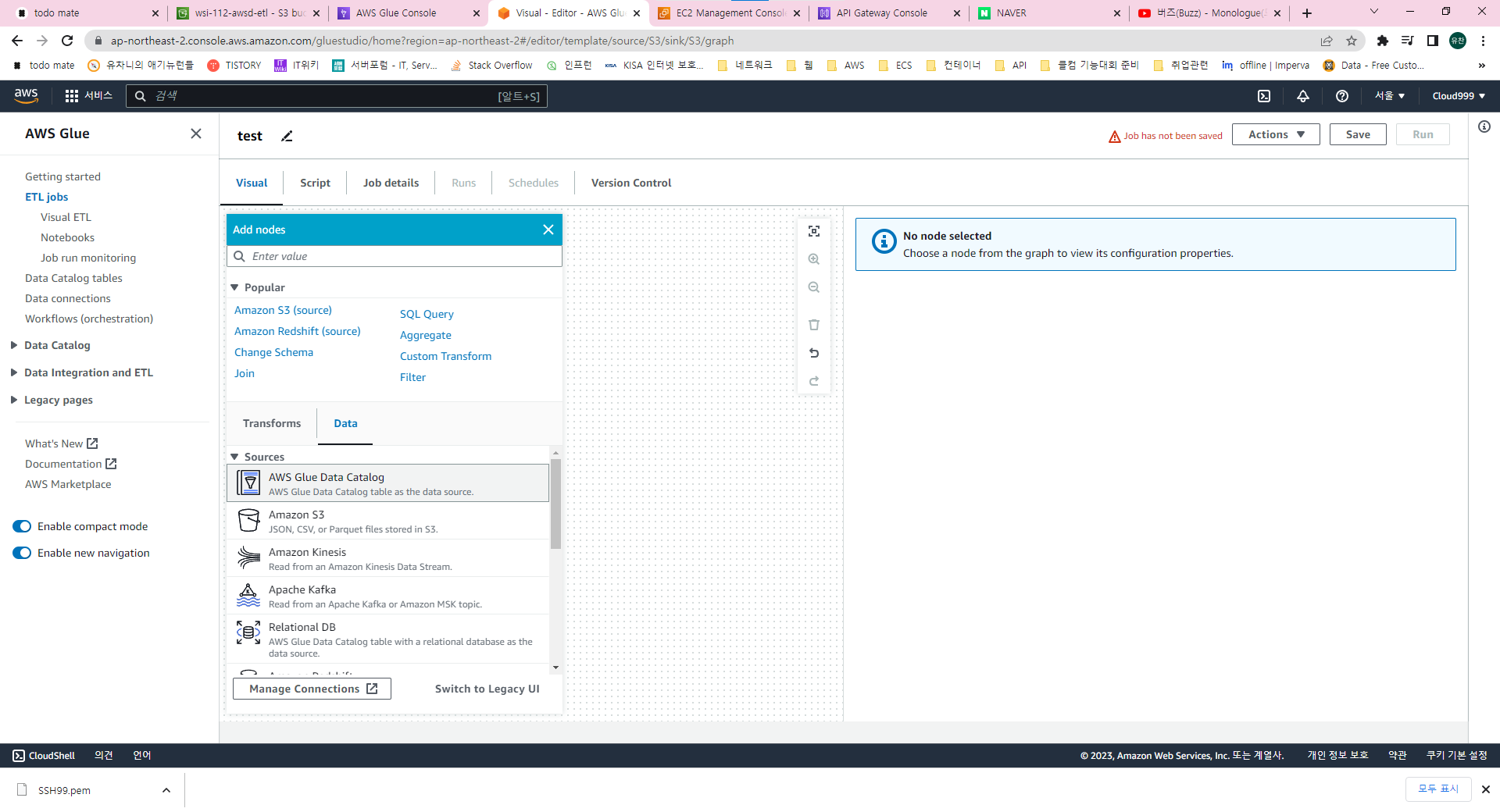
허허 Glue는 그새 또 UI가 변경됐네요 사진 처럼 Glue Catalog 두개 생성해줍니다.
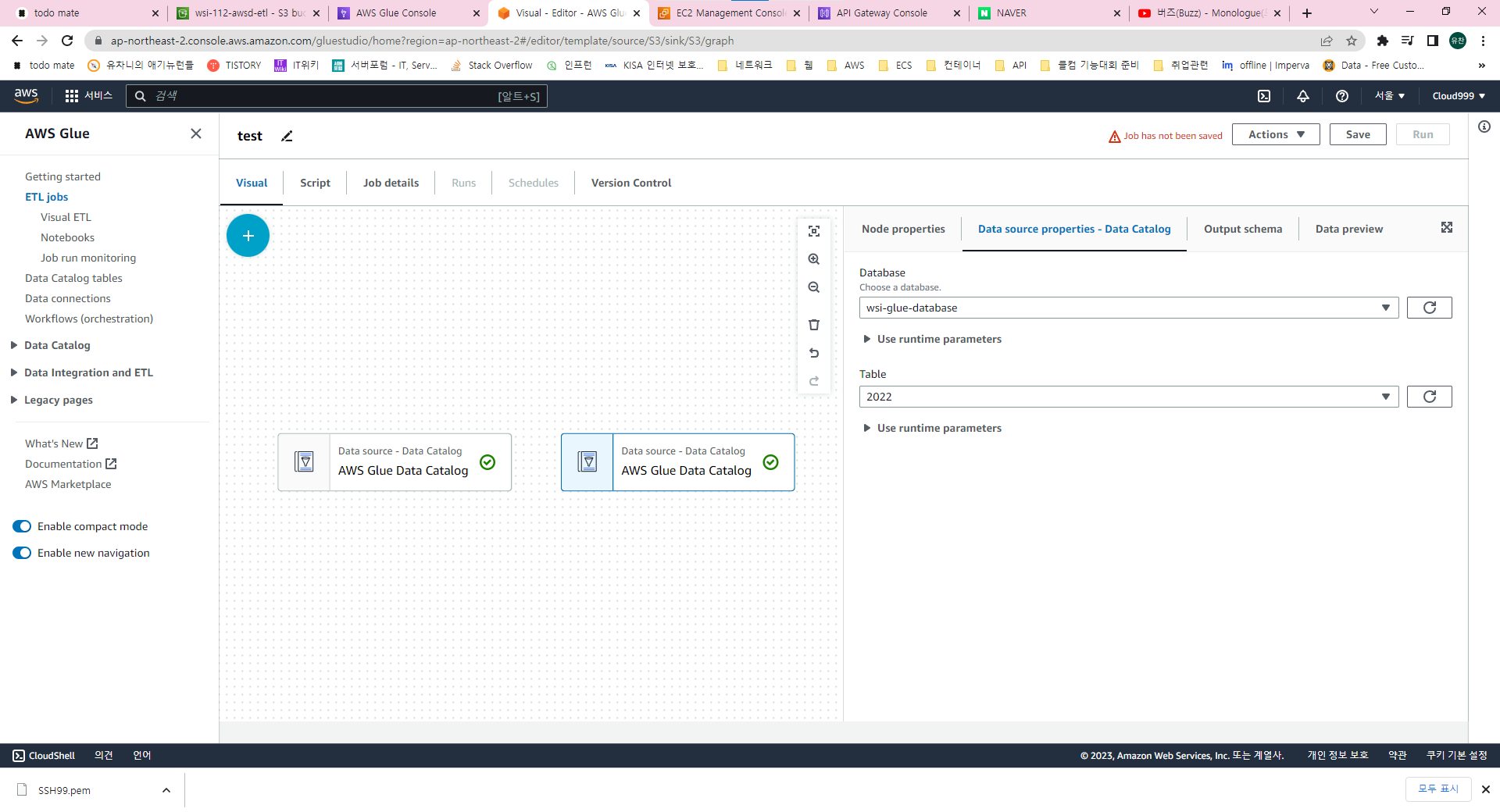
카탈로그를 선택하고 사용할 데이터베이스, 테이블을 선택합니다.
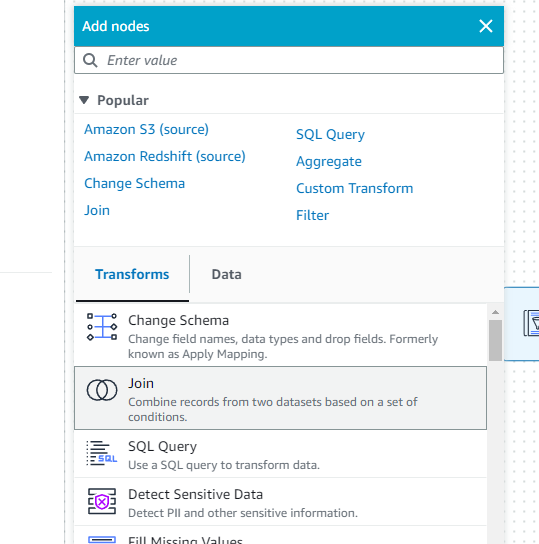
join이라는 친구를 생성합니다.
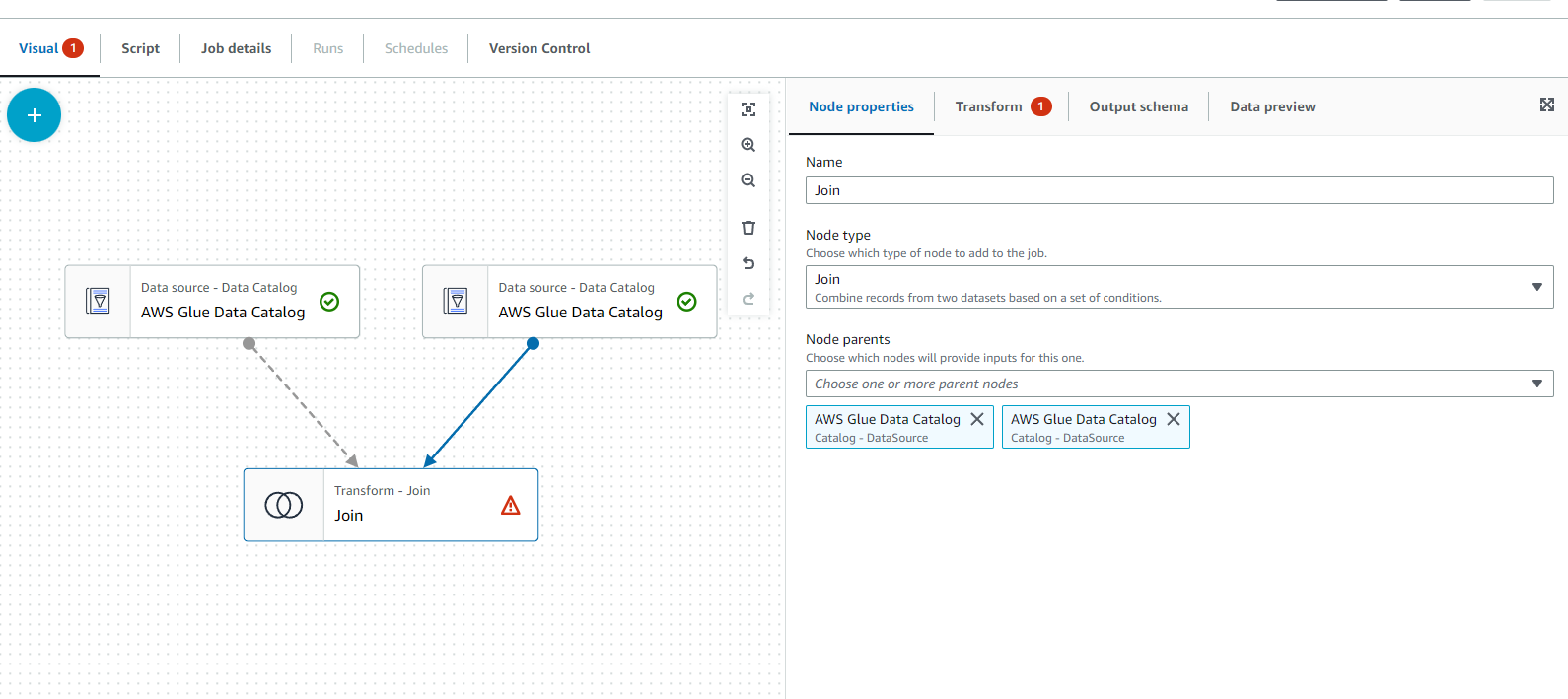
join을 선택하고 node 프로퍼티에서 카탈로그를 모두 선택합니다.
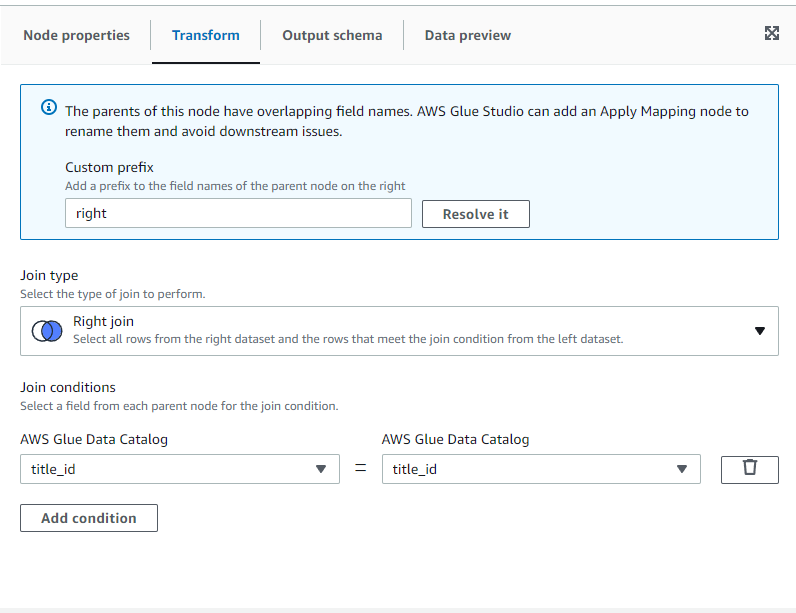
transform 탭에서 right join 선택하고 add condition으로 title_id가 같을때를 선택합니다.
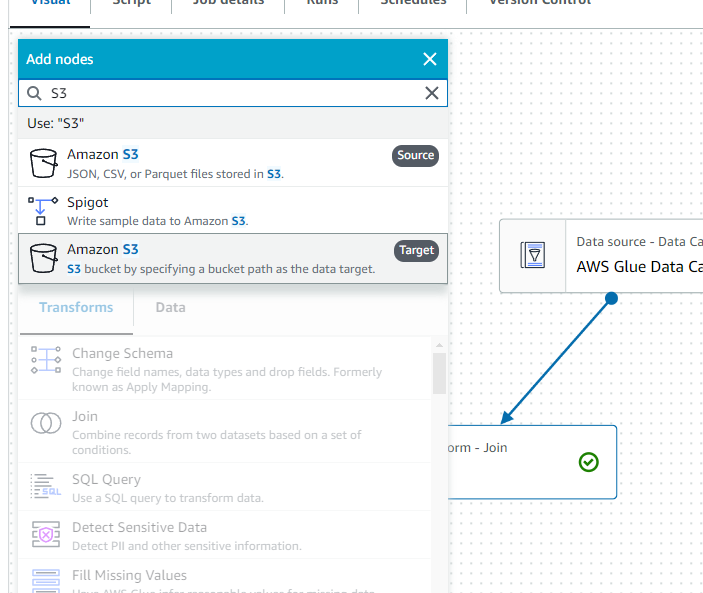
타켓이라고 써져있는 S3를 선택합니다.
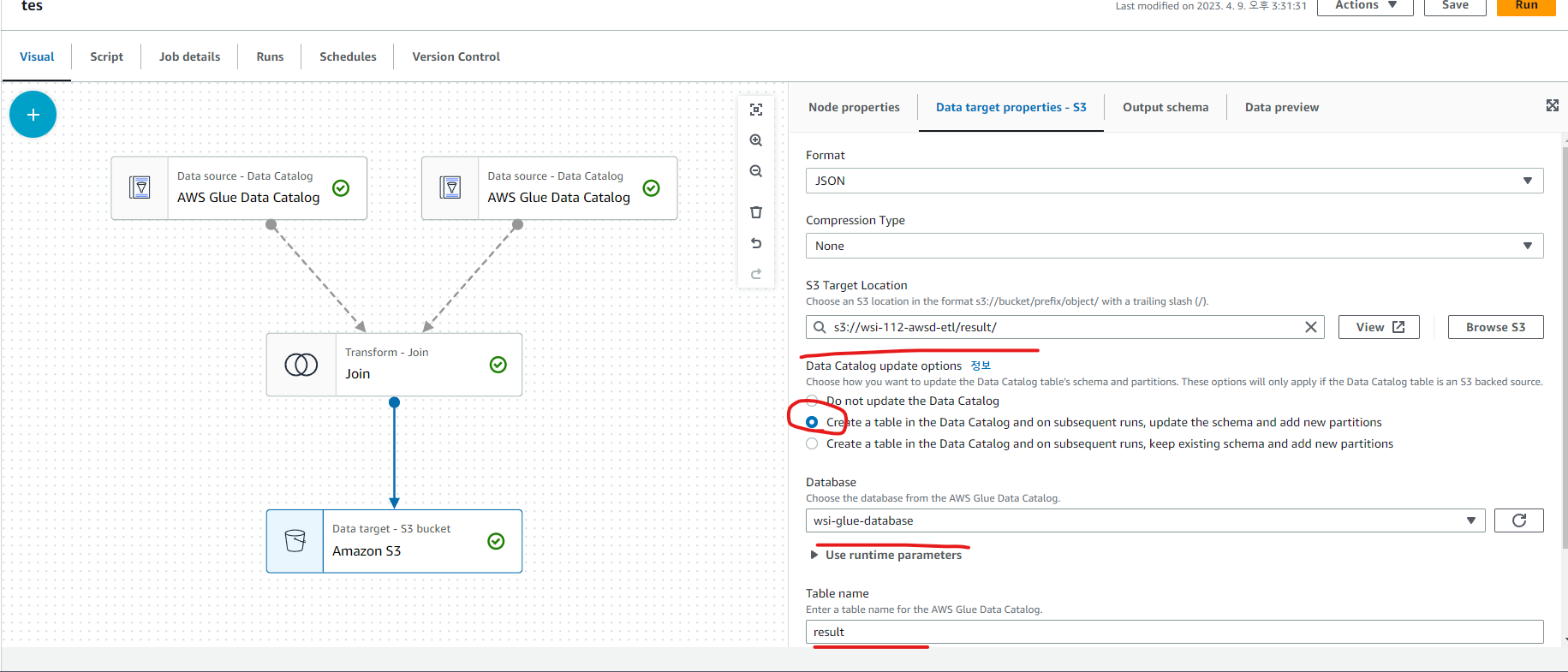
S3에도 저장하고 Glue에도 result라는 테이블이 생성되도록 지정했습니다.
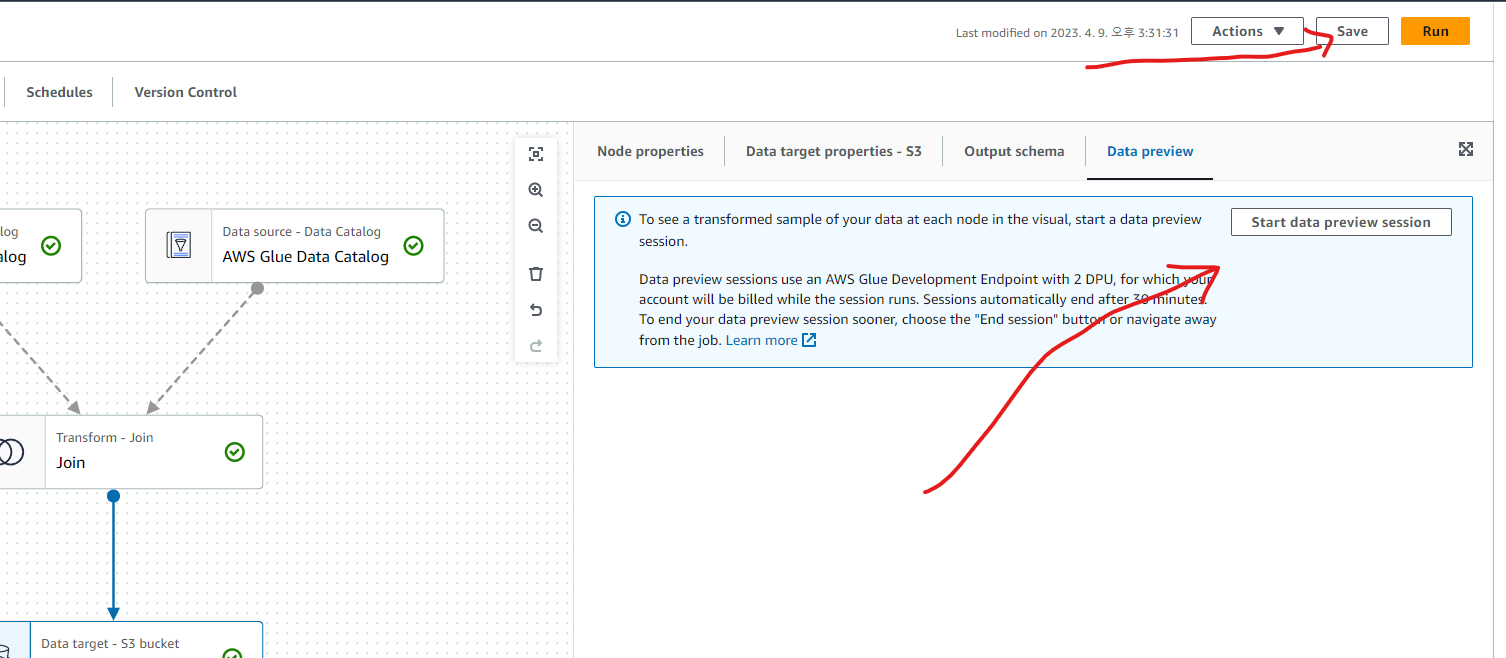
JOB의 내용을 저장하고 한번 테스트 실행을 해보겠습니다. 앞에서 설정했던 gluerole 이용해서 테스트 하면 됩니다.
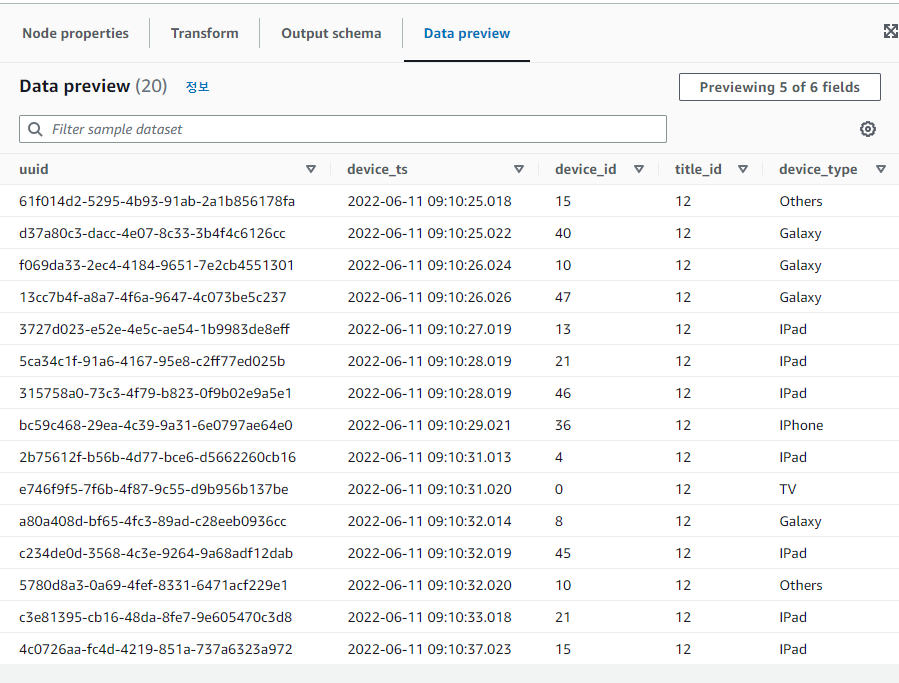
정상적으로 작동하네요 이제 Run을 통해 실행해보겠습니다.
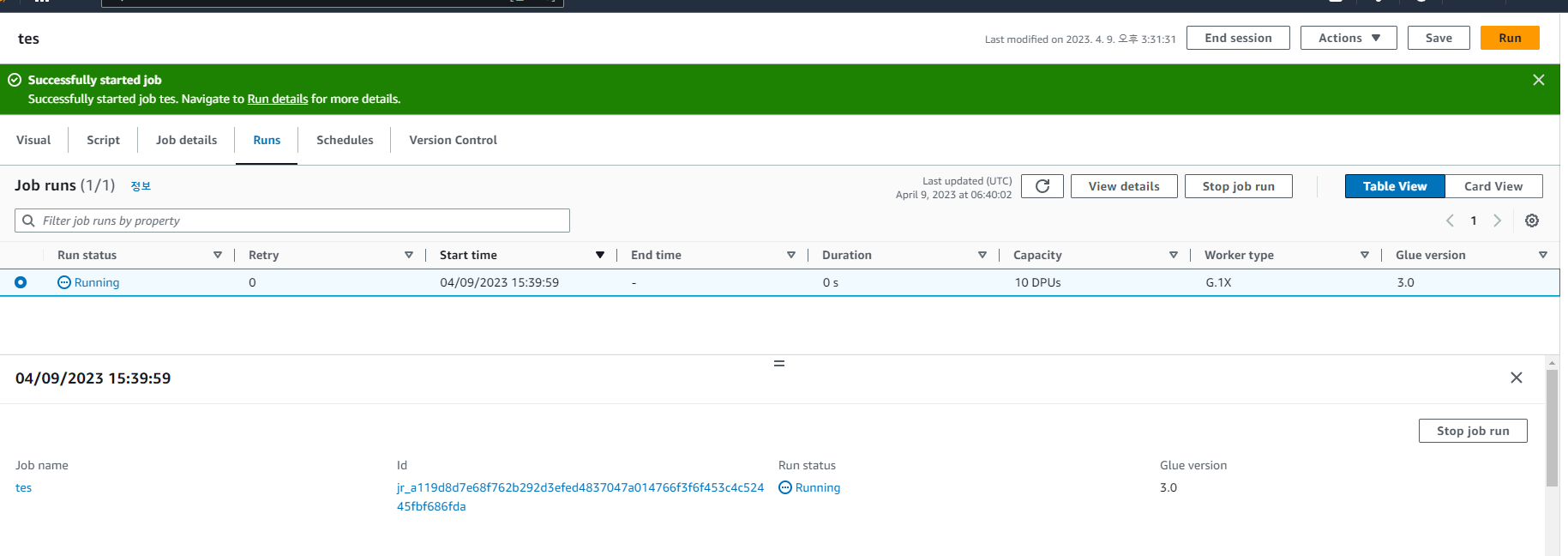
S3에 정상적으로 데이터들이 저장됐습니다.
'네트워크 > 클라우드 컴퓨팅' 카테고리의 다른 글
| AWS CloudWatch로 SSH access logging (0) | 2023.10.19 |
|---|---|
| ALB path based routing(컨테이너 배포) (1) | 2023.04.09 |
| ECS,ECR을 이용한 Flask web 배포 (0) | 2023.04.09 |
| Lambda와 Event Bridge 이용해서 EC2 실행,종료 제어 (0) | 2023.03.16 |
| AWS ECR 컨테이너 이미지 업로드, 다운로드 (1) | 2023.03.15 |